
Editors Note: This is the first of two independent posts on the performance of Intel’s new memory technology.
Disruptive memory technologies are leading to major improvements in both the capacity and bandwidth of memories. When coupled with fast cores, these memories enable us to tackle large-scale problems at much lower cost and power than ever before.
One such memory technology is the Intel® Optane™ DC persistent memory. Intel Optane DC persistent memory modules are like DRAM in form factor and can be configured as volatile main memory, persistent memory or as a combination.
A previous SIGARCH blog post by Steve Swanson titled “A Vision of Persistence” outlined the systems challenges that arise in using Intel Optane DC persistent memory as persistent memory. Another blog post by Joy Arulraj and Spyros Blanas, titled “Data management on non-volatile memory”, considered a database problem and discussed the changes required to fully utilize the potential of new persistent memory technologies.
Figure 1: Intel Optane DC Persistent Memory
Intel Optane DC persistent memory in Memory mode:
In this post, we focus on the Memory mode of Intel Optane DC persistent memory, which extends the cache/DRAM memory hierarchy by acting as another level of volatile memory, providing affordable, significantly larger memory capacity with efficient byte-level access for in-memory applications. Intel Optane DC modules can be configured at up to 3 TB per CPU socket (in addition to the DRAM present in the system), so a 2 socket machines can have as much as 6TB of main memory. In this mode, the DRAM present on the machine acts as cache for the Intel Optane memory.
In-memory large-scale graph analytics:
One application area that can benefit from this new memory technology is graph analytics. Graph analytics systems today must handle very large graphs such as the Facebook friends graph, which has more than a billion nodes and 200 billion edges, and the indexable Web graph, which has roughly 100 billion nodes and trillions of edges. Parallel computing is essential for processing graphs of this size in reasonable time.
Shared-memory graph analytics systems such as Galois and Ligra are good at in-memory graph processing but the size of graphs they can handle is limited by the amount of memory present in the machine. To process graphs with billions of nodes and edges, one of the following methods is commonly employed.
- Use distributed-memory clusters that have sufficient main memory for in-memory processing of the graphs. State-of-the-art systems in this space include D-Galois and Gemini.
- Use out-of-core processing in which graphs reside on secondary storage and portions of the graph are read into DRAM under software control for in-memory processing. Xstream and GridGraph are state-of-the-art systems in this space.
In both approaches, it is usually necessary to rethink algorithms and data structures from scratch. Intel Optane DC persistent memory presents an interesting alternative since shared-memory frameworks like Galois can be used out-of-the-box to process very large graphs using its Memory mode. Our team has been studying this approach on a 2 socket machine with 2nd-generation Intel® Xeon® Scalable processors containing 6TB of Intel Optane DC persistent memory. To get a measure of relative performance, we used the distributed-memory D-Galois system on the Stampede cluster at the Texas Advanced Computing Center (TACC). The kernels used in the evaluation are betweenness centrality (bc), breadth-first search (bfs), connected components (cc), kcore, pagerank (pr), and single-source shortest path (sssp).
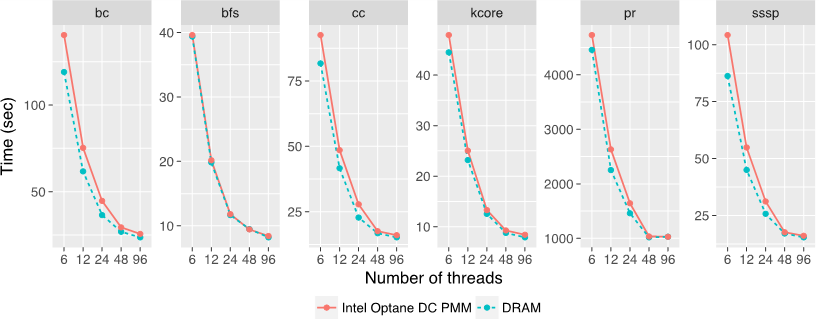
Figure 2: Comparing Intel Optane DC persistent memory performance with DRAM performance for the kron30 graph (1.07B nodes and 10.8B edges)
Figure 2 shows execution times for the kron30 graph, which is generated using Kronecker generator. Kron30 (136GB) fits in DRAM on our machine. For each kernel, we measured the execution times when (i) the graph is stored entirely in DRAM only, and (ii) the graph is stored entirely in Intel Optane DC persistent memory at the start of the computation and brought into DRAM as needed. The results in Figure 2 show that Intel Optane DC persistent memory can deliver performance similar to DRAM.
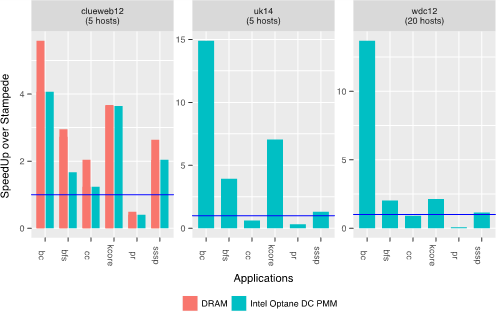
Figure 3: DRAM and Intel Optane DC persistent memory speedups over Stampede cluster for large graphs
For comparison with distributed execution on Stampede, we used clueweb12 (0.98B nodes and 42.6B edges), uk14 (0.79B nodes and 47.6B edges) and wdc12 (3.6B nodes and 128.7B edges), the largest real-world web-crawls publicly available. Figure 3 shows the speedup from using DRAM and Intel Optane DC persistent memory (using 96 cores on a single machine) over using the minimum number of Stampede hosts required to fit the graph (each host has 48 cores and we use all cores on all hosts). The blue line in the plots indicates speedup of 1 over Stampede cluster execution. The minimum number of hosts required for each graph is mentioned in the title of each plot.
We see that the Intel Optane DC persistent memory-based system outperforms D-Galois on the Stampede cluster for all kernels other than page-rank, even though D-Galois uses 2.5x more cores for clueweb12 and uk14, and 10x more cores for wdc12. Page-rank is a compute-intensive kernel and benefits from the additional number of cores in the cluster.
Of course, these large capacity machines come with interesting challenges such as memory management, efficient use of cache hierarchies etc. which may require changes in operating systems, programming models and tools to fully exploit the potential of Intel Optane DC persistent memory.
Exciting times lie ahead for the systems community!
About the Authors: Gurbinder Gill is a PhD student in the Department of Computer Science at the University of Texas at Austin. Ramesh Peri is an architect of performance analysis tools at Intel, Austin. Keshav Pingali is a professor in the Department of Computer Science at the University of Texas at Austin.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
