
GPUs have outgrown their role as dedicated graphics processing units and are now a prominent, mainstream platform for general-purpose parallel computing. Evidence of the growing popularity of GPUs can be seen in cloud vendors offering GPU instances for cents per hour, and the growing fraction (currently 27%) of the top-500 supercomputers using GPUs.
The conventional wisdom is that GPU-based data analytics are only viable when datasets fit in the GPU memory, as datasets in the host memory cannot be transferred to the GPU quickly enough otherwise. The slow transfer speed between the CPU and the GPU is exacerbated by the irregular access patterns of common data analytics algorithms, such as graph traversal and join processing. However, recent work shows that GPUs can now efficiently process datasets that do not fit in GPU memory by complementing software and hardware solutions.
A software solution: optimizing data placement for unified memory
One naive solution to process datasets that do not fit in the GPU memory is to use unified memory. Unified memory is a page fault handling mechanism where a driver transparently transfers a page (4KB) from the host to the GPU when the page is accessed. The driver is not only passively reacting to memory accesses, but can proactively migrate pages to reduce the expected number of faults (prefetching), uses heuristics to avoid migrating shared pages (to mitigate thrashing), and implements an LRU policy to decide what pages to evict to make room for new pages. The application can specify hints to override the default policies for prefetching, thrashing mitigation, and eviction, if needed. One promising research direction considers how one can make data access patterns more regular to maximize the benefit of unified memory and, specifically, its prefetching ability with page-sized data transfers.
An interesting recent paper that was presented at VLDB 2020 focuses on graph analytics and breadth-first search (BFS) traversal on large graphs. The motivating observation is that the BFS traversal of large, sparse graphs in compressed sparse row (CSR) format has excessive read amplification, thrashing, and evictions with unified memory. One can improve locality by reordering the graph labels: first placing nodes within the same frontier close to each other, and then placing successive frontiers close to each other. The challenge is that the node a BFS traversal will start from is not known beforehand, so the placement strategy needs to be “good enough” for any starting node. In addition, directed graphs impose ordering constraints on traversals which makes reordering more challenging. The proposed solution, HALO, uses the notion of centrality in graph theory to rank nodes in a graph based on how close they are to all other nodes, and reorders the nodes in the graph in decreasing order of centrality, as shown in the example below:
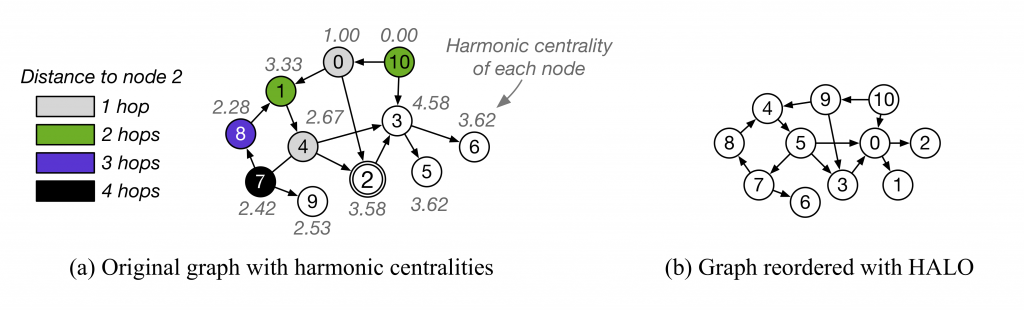
An example of graph reordering with HALO that reduces read amplification, thrashing and evictions with unified memory when doing breadth-first search on graphs that do not fit the GPU memory. Figure from P. Gera et al. “Traversing Large Graphs on GPUs with Unified Memory.” PVLDB, 13(7), 2020.
A performance analysis with several graphs that are larger than the GPU memory shows that HALO speeds up breadth-first search by 1.5×-1.9× on unified memory.
Fast, coherent memory access in hardware
Hardware vendors have recently introduced interconnects with much higher bandwidth to the host memory that often support coherent memory accesses. Examples include the NVLink interconnect from NVidia, the Compute Express Link (CXL) by Intel, the Infinity Architecture from AMD, and the Coherent Accelerator Interface (OpenCAPI) from IBM. Cache coherence has two advantages for data analytics applications: First, data consistency no longer needs to be managed through page migration and careful flushing. Second, atomic operations can now be performed to memory regions that are much larger than the GPU memory.
The non-partitioned hash join has been studied since the earliest days of general-purpose GPU programming and is a great example of an algorithm that can leverage cache coherence between the GPU and the CPU memory. The non-partitioned hash join takes two tables as inputs, and proceeds in two phases: the build phase and the probe phase. During the build phase, all rows from the first table (the build table) are stored in a hash table based on the join key. Atomic operations are used to ensure that two threads don’t write at the same slot in the hash table at the same time. During the probe phase, rows from the second table (the probe table) are used to probe the hash table for matching join keys. A well-chosen hash function should evenly distribute the accesses across all hash table slots, which makes the memory access pattern of the non-partitioned hash join highly irregular. CPU implementations of the non-partitioned hash join suffer from high stall rates because of the poor locality and limited instruction-level parallelism of the algorithm.
A GPU-based implementation can hide the memory access latency associated with the irregular memory access pattern thanks to the high random access throughput of GPU memory. Cache coherence allows the algorithm to scale to input sizes that are much larger than the size of the GPU memory: If the build table does not fit in GPU memory, a fraction of the hash table will be transparently spilled from GPU memory to host memory. If the probe table does not fit in GPU memory, the high sequential bandwidth between the host and the GPU maintains the performance advantage of the GPU compared to a CPU-only implementation. Finally, system-wide atomics permit sharing the hash table between the CPU and the GPU and processing it cooperatively.
A recent paper published in SIGMOD 2020 (and also awarded best paper) shows that by leveraging coherence a GPU with NVLink 2.0 can execute the non-partitioned hash join 6× faster than a CPU or an earlier-generation GPU, even when the dataset is much bigger than the size of the GPU memory:
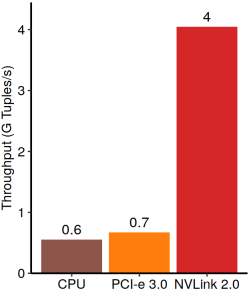
The throughput of the non-partitioned hash join on a GPU with NVLink 2.0 is 6× higher even when the dataset is much bigger than the size of GPU memory. Figure from https://e2data.eu/blog/fast-gpu-interconnects.
Towards GPU-enabled data analytics
Although early work established the superiority of GPUs in specific data analytic tasks, it also showed that the slow data transfer rate between the CPU and the GPU would limit the role of GPUs for data analytics to datasets that comfortably fit in the GPU memory. Recent work shows that coupling careful data placement with fast, coherent interconnects makes GPUs a promising data analytics platform for datasets that do not fit in the GPU memory. Other interesting research in this space includes compression (both in software and in hardware), and encapsulating parallelism in a uniform manner. The pace of software and hardware innovation points to a bright future for GPU-enabled data analytics.
About the author: Spyros Blanas is an Associate Professor in the Department of Computer Science and Engineering at The Ohio State University. His research interest is high performance database systems.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
