
Picture generated by Microsoft Designer powered by DALL·E 3
Computations on sparse matrices/tensors in scientific computing, graph processing, and deep learning are one of the earliest and most studied algorithms for hardware acceleration. Such sparse computations are inefficient on general-purpose CPUs and GPUs due to irregular data patterns, which result in low locality and cannot leverage cache hierarchies. The irregularity also leads to load imbalance when parallelizing computations across multiple processing cores/units. Therefore, sparse computations are challenging as it is difficult to exploit two of the most effective architectural optimizations today: locality and parallelization. Many specialized hardware architectures are thus proposed to alleviate these issues and boost the performance and efficiency.
The literature of sparse accelerators is enormous. In this post, I would like to take a perspective of dataflow, which is extended from their counterpart of dense accelerators. In a previous post, I have discussed the dataflow techniques in (dense) neural network accelerators and generalized them to larger scales at the system level. Loop tiling (a.k.a., loop blocking) and loop reordering are the two most popular dataflow transformations in hardware accelerator design and software tensor compilation. We thus focus on these two techniques and illustrate their applicability to sparse accelerators.
Loop reordering in sparse accelerators
Recent accelerators for sparse matrix multiplications mostly follow three types of dataflow schemes, known as inner-product (e.g., SIGMA, Cambricon-S), outer-product (e.g., OuterSPACE, SpArch), and row-based (i.e., Gustavson’s, e.g., Gamma, MatRaptor). If we think of them in terms of the nested loop structure with loop M, N, K (here matrix A is M × K, B is K × N, and C is M × N), then these three schemes actually correspond to the loop orders of M → N → K, K → M → N, and M → K → N, as shown in the figure below. One may notice that with three loops, there should be 3! = 6 different orders. Indeed, the rest of the three orders are dual to the three orders shown below. For example, with the order of N → K → M, we actually iterate each element in matrix B along the column dimension, and do scalar-vector multiplications with the corresponding column in matrix A, to obtain a partial sum column of the result C. This is the column-based dataflow, dual of the row-based one.
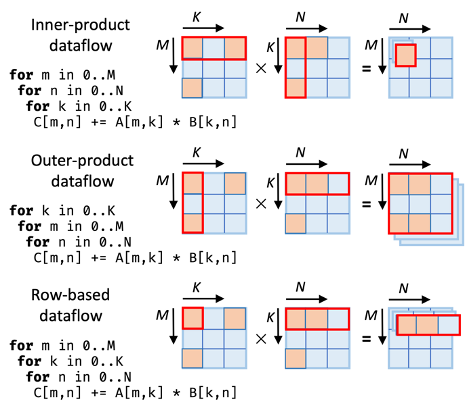
Sparse matrix multiplication dataflow schemes represented as different loop orders. Figure from Spada.
Just like different loop orders result in different data reuse behaviors in the dense case, the three dataflow schemes also exhibit diverse preferences to the three input/output matrices. Take outer-product as an example. As the M and K loops are at the outer levels, when the innermost loop N iterates, the input matrix A element does not change, and thus has prefect reuse over all the N iterations. However, the output matrix has poor reuse. In fact, inner/outer-product dataflows have excellent data reuse for the output/input matrices, respectively, while row-based dataflow achieves a better balance in between. In addition, inner-product has other drawbacks such as inefficient index intersection, besides data reuse behaviors.
Loop tiling in sparse accelerators
In the dense case, loop tiling splits a dimension into multiple (e.g., two) levels, effectively dividing the matrix/tensor into smaller blocks. Different from the original large matrix/tensor that exceeds the cache size, these small blocks allows for more efficient caching, which lets them stay on-chip and be extensively reused.
When loop tiling is applied to sparse matrices/tensors, there are two distinct iteration spaces that can be tiled: the original coordinates (including both zeros and nonzeros), and the positions in the contiguously stored nonzero elements. Accordingly, two tiling approaches are available as shown below: coordinate-based tiling applied to the original coordinates, and position-based tiling applied to the actual storage layout of nonzeros.
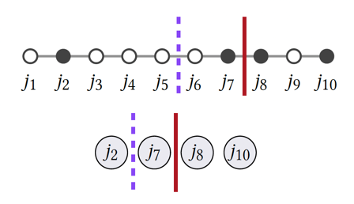
Coordinate-based vs. position-based tiling. At the top, black dots denote nonzero elements. The purple dash line shows even coordinate-based tiling; the red solid line shows even position-based tiling. Figure from taco.
The tradeoffs are easy to see. Coordinate-based tiling can split the original sparse matrix into regular-shaped sparse blocks, e.g., a sparse matrix of 100 × 100 can be decomposed into 100 blocks, each of which is 10 × 10 and also sparse. This is particularly important when two matrices are contracted (i.e., multiplied) together, where the two matching dimensions of the two inputs (e.g., dimension K for matrix multiplication between M × K and K × N) must be tiled in the same way (i.e., co-tiled) so they can be co-iterated. However, the drawback of coordinate-based tiling is the uncertain number of nonzeros in each block, which leads to highly varying data volumes across blocks and is difficult to match with the on-chip buffer capacity. More nonzeros than the buffer size result in thrashing, while fewer nonzeros cause buffer space underutilization.
Dynamic adoption to rescue
As we can see from the above, directly extending loop tiling and reordering techniques to sparse accelerators raises additional challenges. Applying them in a static way that is oblivious to the sparse data pattern is unlikely to achieve the best efficiency. More specifically, since different loop orders (dataflow schemes) exhibit different reuse degrees to different matrices, their efficiency would highly depend on the sparse matrix patterns, e.g., which one of input and output is more sensitive to data reuse. On the other hand, when using coordinate-based loop tiling, the variation of block size, and thus the utilization of buffer space, is directly determined by the local sparsity of the corresponding matrix region.
We therefore advocate that extending dataflow techniques from dense to sparse accelerators requires dynamic designs that could adapt to sparse data patterns. Several recent research works have been already exploring along this path. We briefly discuss two representatives. We believe that more future designs would follow the direction and further enrich the landscape.
First, Spada is a sparse matrix-matrix multiplication accelerator with adaptive dataflow, that can dynamically select among different dataflow schemes (loop orders) based on the specific data sparsity patterns. With a novel window-based dataflow template, different dataflows can be realized by specifying different window shapes. An online runtime routine profiles the data to decide the best window shape, and accordingly reconfigures the hardware components. In such ways, Spada is able to match the best performance among the three loop orders on a wide variety of sparse matrices.
Second, DRT (dynamic reflexive tiling) is a dynamic loop tiling method for sparse data orchestration. It follows the coordinate-based tiling approach to enable efficient tensor contraction. Nevertheless, instead of statically choosing a uniform block size, DRT dynamically determines the block size based on the sparsity of the current data region, to fully utilize the available on-chip buffer space. For example, sparser regions could use larger block sizes, hence effectively resulting in relatively stable nonzero data volumes and enjoying the key benefit of position-based tiling.
Other challenges beyond our scope
The loop transformation techniques (tiling, reordering, etc.) discussed above are just parts of the full picture. Sparse accelerator design presents many more challenges that are beyond the scope of this post. To name a few: first, many sparse formats (e.g., CSR, CSC, COO, ELL, and their blocked variants) exist, and different formats enable/disable efficient iterations along certain dimensions. How to convert between formats (e.g., taco), and further how to choose the most efficient dataflow on the specific format (e.g., Flexagon), are critical topics. Second, despite the tremendous efforts of optimizing buffer utilization like in DRT, the on-chip buffer cost (in terms of chip area) remains dominant. Is there a way to reduce the required buffer capacity without sacrificing efficiency? Third, from the algorithm’s perspective, it has been demonstrated that many deep learning models can be pruned in a structured fashion so the sparse tensors exhibit some regularity and can be more efficiently processed. How to balance between generality and efficiency for structured vs. unstructured sparsity is still debating. In summary, even though sparse acceleration is one of the oldest architectural topic, many opportunities still exist and await comprehensive investigation.
About the author: Mingyu Gao is an assistant professor at the Institute for Interdisciplinary Information Sciences (IIIS) at Tsinghua University. His research interests lie in the fields of computer architecture and systems, including efficient memory architectures, scalable acceleration for data processing, and hardware security.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
