
 “The growing complexity of intelligent systems can outpace the ability of conventional computing abstractions to support them effectively.” IET REACH 2024, Amir Yazdanbakhsh.
“The growing complexity of intelligent systems can outpace the ability of conventional computing abstractions to support them effectively.” IET REACH 2024, Amir Yazdanbakhsh.
I came across this observation by Edsger Dijkstra recently while scrolling X, and it stopped me in my tracks:
“The purpose of abstraction is not to be vague, but to create a new semantic level in which one can be absolutely precise.“
It made me ponder the role of abstraction in the age of AGI. It captures the essence of abstraction: not to obscure complexity but to tame it—making intricate systems comprehensible, predictable, and ultimately usable. As architects, we have long relied on carefully designed abstractions to manage complexity in the computing stack.
But as we consider the potential of intelligent systems, I’m curious: Are our traditional abstractions up to the task? How do we navigate the growing complexity of systems that blend von Neumann and non-von Neumann architectures, symbolic reasoning, and neural networks and evolve dynamically, learning from their environments and improving themselves over time? This shift echoes how human intelligence has evolved–constantly shaped by feedback, self-reflection, and adaptation.
Alan Turing once imagined a “machine that learns from experience.” Today, we’re seemingly closer to bringing that vision to reality. The systems of the future won’t just follow static instructions; they’ll adapt, improve, and evolve, much like we do. This shift forces us to rethink the very foundation of how we design and build them. If the computing stack were the framework for the Industrial Revolution of information, what abstractions would guide us in the age of self-improving, feedback-driven intelligence? What abstractions enable us to tame the complexity of intelligence? These are not just technical questions but ones that touch on the philosophy of intelligence, computation, and computer system design.
Rethinking Abstractions for Intelligent Systems
Recently, after discussing with some colleagues, a seemingly simple question was raised: What are the necessary abstractions for intelligent systems? Should we rethink the conventional abstractions, or can we repurpose the tools we’ve used for decades? These questions are critical because they reveal a broader curiosity about how to approach the evolving landscape of such systems.
This post leans toward the argument that we need to rethink these abstractions, as intelligence is generally probabilistic and non-deterministic. Designing intelligent systems should prioritize embracing uncertainty and dynamically adapting to evolving environments as its core principles. Some questions worth pondering include: (i) what forms of probabilistic/non-deterministic outputs exist at various abstraction layers? (ii) how and when do they bleed through abstraction boundaries? and (iii) what guarantees do systems provide, and what metrics do we need to define (or invent) to track them?
The Anatomy of a Potential Intelligent Systems
Now, AGI might come in all sorts of flavors. But for this discussion, I’ll stick with the concept of compound AI systems as a potential recipe for success. That said, I can’t shake the feeling that, beneath the surface, the anatomy of any intelligent system likely stems from the same fundamental ingredients.
A compound AI system is built on the principle of modularity. Each subsystem is focused on a specific task. One module may excel at image recognition, another at language comprehension, and yet another at decision-making, planning, or long-term memory. These modules are independently optimized for their respective roles, but their real power emerges through interoperability—their ability to share data, predictions, or intermediate results. Picture a vision module analyzing spatial data and passing it to a planning module.
Compound AI systems thrive on diverse approaches, blending different AI paradigms to solve problems holistically. Neural networks may handle pattern recognition, symbolic reasoning tackles logical inferences, and RL may optimize decision-making and planning. This diversity ensures that the system can address problems from different perspectives.
When different systems work together, their combined abilities go beyond what they could do in isolation. This idea isn’t new—Marvin Minsky described the mind as a “society of mind,” where simple parts interact to create complex behaviors. The same applies to AI. Take a language model, for example—on its own, it generates text, but when paired with a knowledge graph, it can answer questions and explain its reasoning. Remembering that intelligence comes from collaboration between different components, not just raw capability, is a helpful context.
The most fascinating quality of intelligent systems is their adaptability to different scenarios. Like human intelligence, these systems are not static; they can learn, adapt to new data, reallocate resources, and be fine-tuned to achieve different goals. For example, a module initially designed for image classification might be fine-tuned for medical imaging. This adaptability is a defining feature of intelligence—both artificial and human.
Finally, compound AI systems are designed to mirror the way human intelligence works. Just like we use a mix of perception, memory, reasoning, and creativity to make sense of the world, these systems combine diverse cognitive abilities to handle complex tasks. The goal is to create AI that doesn’t just process information but understands it better.
Designing Principles for New Abstractions
One of the biggest challenges in designing these abstractions is finding the right balance between generality and specificity. They must be broad enough to support different types of interactions but still precise enough to convey meaning precisely. The real question is: How do we make these interactions flexible without overwhelming the system with unnecessary complexity?
The next part is information representation. Different subsystems can operate on various data types—structured knowledge, raw sensory inputs, or probabilistic estimates. Choosing the proper representation is crucial to preserving the data’s richness while ensuring compatibility between components.
Next is scalability. As the number of subsystems grows, their interactions become more complex. Abstraction layers must handle this growth efficiently without becoming a bottleneck that slows everything down.
Such systems also operate in dynamic environments, requiring real-time updates and adaptive behaviors. Abstractions must allow components to modify their behavior or interfaces in response to shifting contexts, such as humans adapting their communication styles based on the situation.
A critical issue is error propagation. Even minor errors in one component can cascade through the entire system, more pronouncedly in a tightly connected system, amplifying problems. Robust abstractions must act like firebreaks, containing errors and maintaining the system’s stability even when some components falter.
Making different types of models work together smoothly is a real challenge. Each subsystem might be built on a completely different foundation—neural networks, symbolic reasoning, statistical methods, or other tools. Designing abstractions that facilitate seamless communication between these heterogeneous components is like creating bridges between entirely different ways of thinking.
Other essential components include minimizing dependencies. Subsystems must function independently yet integrate seamlessly. Interpretability and debugging are also critical. Poor abstractions can obscure a system’s inner workings, making it challenging to understand, debug, or improve.
Bringing multiple modalities together—vision, language, and audio—adds another level of complexity. It’s not just about processing them individually; they need to work together seamlessly, complementing each other rather than competing. Another key challenge is figuring out how to learn and refine abstractions automatically. Systems must adapt quickly, tweaking their inferences based on real-world feedback and unexpected inputs. And none of this happens in isolation—bringing everything together requires insights from different fields, from machine learning and systems engineering to cognitive science. The real magic happens at the intersection of these disciplines.
What the Computing Stack Teaches Us About Complexity: A Case Study
Drawing parallels between the computing stack and the abstractions for intelligent systems may not present a perfect analogy. However, it offers a helpful way of thinking about the layers and relationships in these systems. Intelligent systems bring complexities far beyond traditional computing, and no blueprint exists for abstracting them effectively. That said, looking at the computing stack can provide a helpful starting point.
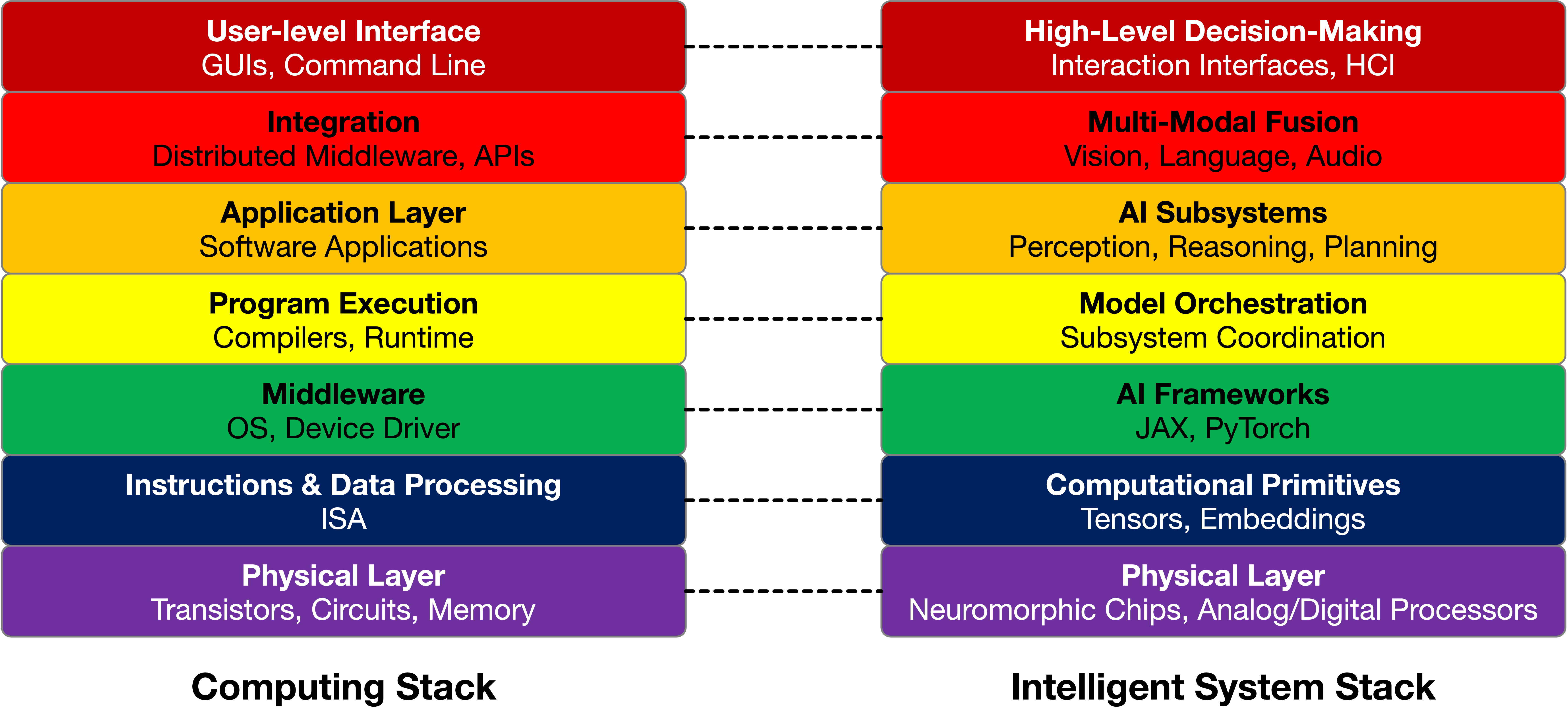
The traditional computing stack on the left provides carefully designed abstractions over decades. On the right, we envision the stack for intelligent systems, where each layer must handle the challenges of multi-modal data, dynamic adaptation, and emergent behavior. The two stacks align in some areas, but as we climb higher, we see the unique complexities of intelligent systems.
The physical layer is at the base of the computing stack. It is similar to neuromorphic chips, von Neuman architectures, ML accelerators, and analog components in intelligent systems.
The instruction and data processing layer is where the ISA provides a bridge between hardware and software. In intelligent systems, this corresponds to computational primitives, such as tensor operations, embeddings, or feature maps, which act as the interface for data and operations in models.
The middleware and frameworks layer in to make computing more accessible. Operating systems and device drivers abstract hardware complexity, giving developers clean APIs to work. The same idea applies to intelligent systems—AI frameworks like Jax or PyTorch play this role. They take care of the complexity under the hood so users can focus on building and training models instead of worrying about low-level optimizations.
Next comes program execution. In intelligent systems, this layer involves model orchestration layers, which manage interactions between AI components, such as routing data between vision, language, reasoning, planning, and memory modules.
At the application layer, the computing stack delivers functionality to end users. In intelligent systems, this is represented by AI subsystems, such as perception, reasoning, and planning modules. Each solves specific tasks while interacting with others through carefully defined abstractions.
Then, we see the integration and interaction layer. In the computing stack, this involves middleware for distributed systems. This layer is responsible for multi-modal fusion for intelligent systems, integrating outputs from diverse AI components, such as combining visual and textual information to create richer insights.
Finally, a user-level interface corresponds to high-level decision-making and interaction interfaces in intelligent systems. It exposes actionable insights and enables natural interactions through conversational agents or autonomous and intelligent systems.
Yet, as we draw these comparisons, the unique challenges of intelligent systems become apparent. Unlike the largely static abstractions of the computing stack, intelligent systems must operate in dynamic (and potentially non-deterministic) environments, requiring abstractions that can evolve and adapt in real time. They must also contend with heterogeneity, handling diverse modalities like vision, language, and audio at every layer. Furthermore, intelligent systems must support emergent behavior, enabling subsystems to interact in ways that produce new capabilities. And, perhaps most critically, they must be designed for error and uncertainty tolerance, gracefully managing uncertainty and imperfections in a way that the deterministic computing stack rarely has to face, the same as the resiliency in human intelligence.
Despite its limitations, the computing stack may provide a valuable lens for understanding and developing necessary abstractions for future intelligent systems. However, it also challenges us to innovate for a new era where systems evolve into adaptive and intelligent agents. As we build the stack for such systems, the main questions remain: What will its abstractions look like, and how will they define the structure of intelligent systems? What new computational primitives could be introduced to better align hardware with the unique requirements of deep learning models? Can model orchestration layers enable robust communication between diverse AI modules? How can we design instruction sets that natively support multi-modal data processing and tensor operations? What abstractions can ensure emergent behaviors align with user expectations? How can AI frameworks like JAX and PyTorch evolve to abstract hardware complexity for systems with heterogeneous architectures? etc. — Alas, I don’t have the answers yet, but these questions may be a good start!
Acknowledgements:
I want to thank my colleagues and collaborators for their valuable feedback and insights while developing the ideas for this post. Thanks to Herman Schmit, Suvinay Subramanian, Cliff Young, Tushar Krishna, Vijay Janapa Reddi, and Shvetank Prakash for their valuable suggestions. Additionally, part of this discussion stems from recent interactions with colleagues after attending a panel at the IET REACH conference, which provided valuable perspectives. This post also draws inspiration from the ideas presented in “AI Software Should Be More Like Plain Old Software“, “Architecture 2.0: Why Computer Architects Need a Data-Centric AI Gymnasium,” and “The QuArch Experiment: Crowdsourcing a Machine Learning Dataset for Computer Architecture.” Finally, I thank the SIGARCH blog editorial team for their guidance and support.
About the Author:
Amir Yazdanbakhsh is a research scientist at Google DeepMind. His innovations have resulted in multiple headline hardware features across several generations of Google TPUs. Amir is the co-founder and co-lead of the Machine Learning for Computer Architecture team, which leverages the recent machine learning methods and advancements to innovate and design better hardware accelerators.
Author Disclaimer:
While writing this blog post, I used AI models to revise the text and find relevant references and notes. The views expressed in this post are my own and do not necessarily reflect those of Google DeepMind.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
