
Large Language Models (LLMs) and other foundation models have revolutionized what is possible to implement in software. On a regular basis, new AI models with ever greater capabilities, such as converting text to video, are rolled out. This disruption is so striking that new terminology is needed. We refer to traditional software – the kind that does not call LLMs at runtime – as Plain Old Software (POSW). We call software that exploits LLMs during execution as AI Software (AISW).
One key reason we distinguish these two types is that, even though AISW greatly expands the kind of software that is possible to implement, AISW relinquishes the guarantees we have become accustomed to with POSW. Systems researchers have invested decades of effort into ensuring that POSW has robustness, privacy, security, and other guarantees that are implemented throughout the system stack. For example, hardware supports a separation of code and data with an “execute bit” that can successfully prevent many code exploit attacks. But AISW is susceptible to analogous attacks. AISWs are driven by prompts. If a prompt includes both a task description (“summarize this document”) and data (the document itself), AISWs can suffer from a “prompt injection” attack because they cannot easily determine if the document also contains additional potentially adversarial commands.
Carrying over the guarantees of POSW to AISW will require engagement and innovation from the research community and other disciplines across computer science including HCI, AI, etc. Only through a deep collaboration between these communities can these challenges be overcome. We outline here some of the implications of the shift from POSW to AISW to inform researchers on the needs and challenges of building a robust AISW infrastructure going forward.
We believe the familiar system stack that hasn’t changed dramatically in many decades must be reinvented with AISW in mind:
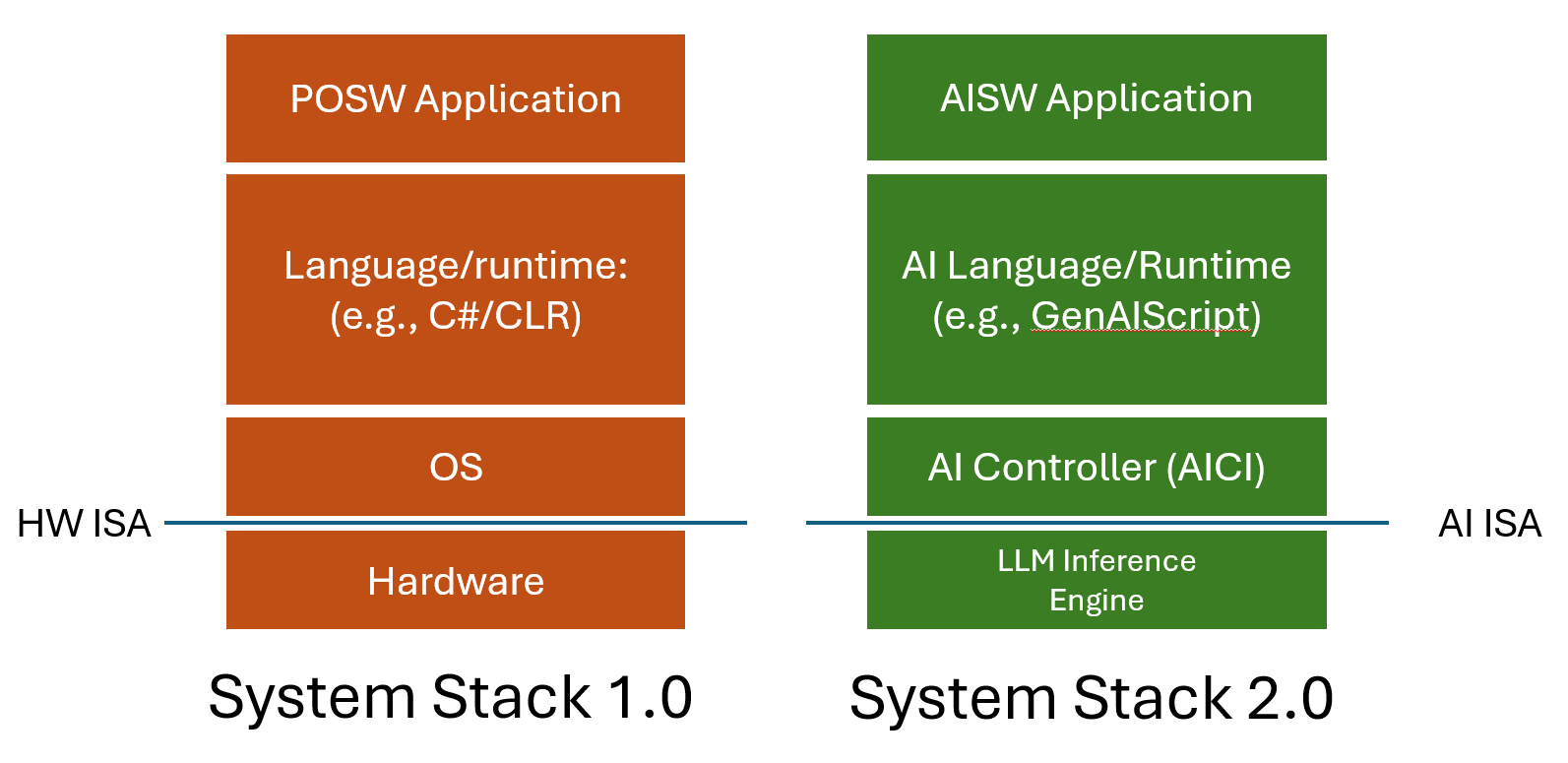
The parts of this new stack are analogous with the old stack, but also different in important ways. The LLM inference engine interfaces the LLM to the stack above it via an interface that includes the prompt context and a “generate next token” instruction. In traditional hardware, think of the prompt context as defining the location of the program counter and the “generate token” action as executing the next instruction. The AI controller manages what “instructions” can be executed by explicitly limiting what tokens the LLM is allowed to generate, much as an OS can prevent certain instructions in privileged mode. The prompt runtime is a set of services that are used to create the final prompt sent to the LLM and parse the resulting generation. Retrieval Augmented Generation (RAG), where additional content from external sources (like documents or the web) is added to the prompt, is an important part of every prompt runtime. Validating generations for correctness, when possible, is another important element of the prompt runtime.
To understand how this new stack differs from the old one, consider this simple AISW application that can be implemented in single sentence: “Given this research paper <attach the paper.pdf> and an organization <name a university, program committee, etc.>, give me 5 individuals in that organization that would be interested in reading this paper.”
This “program” can be implemented in ChatGPT or other existing LLMs with an interactive chat dialog. Having the user in the loop (who understands the standard disclaimers about hallucinations, etc.) provides a level of robustness to the program making it usable. But such a level of review and human intervention defeats the purpose of automating such tasks and is only necessary because the infrastructure supporting robust AISW is only starting to emerge. Right now, it is not obvious how one would transform this chat session application into a robust service. Our goal is a world where, from the perspective of a user, AISW “just works” like POSW.
Two key approaches that existing systems use to solve this problem are specification/verification and standardization. Let’s consider each issue in turn.
First, how do we specify and verify the output of an LLM? Several approaches to specifying both the syntax and semantics of LLM generations have been proposed and implemented. Constraining the output of an LLM to a particular well-formed syntax has clear value when generations are expected to be in JSON format, for example; this approach is supported by libraries like Pydantic Validators. Newly proposed languages like LMQL and Guidance provide “prompt-as-programs” approaches that specify constraints over LLM output as well as conditional execution paths in prompts, depending on the results produced by a previous round of prompting the LLM. These approaches constitute the evolution of the Prompt/Prompt Runtime and AI Controller parts of System Stack 2.0 shown above.
Syntax validation is only a small part of the deeper challenge of specifying and verifying constraints on LLM outputs that are not expressible using existing mathematics. How do you measure whether an LLM summary is faithful to the original content, or that an individual would truly be interested in reading your paper? These are not new questions and ideas for solutions pre-date the rise of LLMs. More than 10 years ago, the Automan project considered how to leverage crowdsourcing to implement functions that could not be computed with POSW. The solution acknowledged that the source of information (humans in the crowd) was inconsistent and potentially unreliable, much as LLMs are today. We believe that increasing the reliability of LLM generations will also involve some of the statistical techniques explored in Automan as well as leveraging potentially many different AI models focusing on different aspects of correctness. Techniques to go beyond ensuring syntactic constraints have also recently been explored, including the concept of Monitor-Guided Decoding (MGD) which uses static analysis to impose semantic constraints on generations.
Standardization in different layers of a stack allows innovation above and below the interfaces. We are familiar with existing HW instruction set architectures, like ARM and x86. These standard interfaces have existed and supported incredible changes in the technology both above and below them for over 40 years. What are the new standard interfaces for AISW? We believe one possible layer in System Stack 2.0 is a token-by-token interface between the prompt language runtime and the LLM. While at the level of ChatGPT, we see an entire prompt and response from the LLM, the interaction could instead happen a token at a time. Each time a token is generated, the calling program would have the opportunity to constrain what the LLM can generate.
Controlling the LLM at this level in a standard way is the focus of the recently released AI Controller Interface project. For example, using a controller like AICI, a prompt can specify that the output must be syntactically correct JSON (or any other language specified in a context-free grammar) and guarantee that it is. Similarly, the prompt can request the model to extract an exact quote from a document and guarantee that the LLM response does not hallucinate the output.
We believe that the co-development of emerging prompt-as-programming languages, like LMQL; standard interfaces, like AICI; and open source implementations of the underlying AI inference stack (such as the Berkeley vLLM project) are emerging technologies that are beginning to define what System Stack 2.0 will be.
This is a call to action for the systems community to embrace the importance of AISW on the future of systems and to focus effort across the community on ensuring that we incorporate state-of-the-art design and implementation as quickly as possible into these systems. The explosive growth of ChatGPT usage illustrates how quickly new AI technology can be invented and deployed. We anticipate rapid advances in the AI state-of-the-art going forward, which highlights the need for the systems research community to continue defining strong, durable abstractions around such systems that can form a basis for ensuring their security, robustness, etc. independently as the models evolve.
AISW will evolve and embed itself increasingly in many aspects of society and, as a discipline, the systems research community has a once-in-a-lifetime opportunity to ensure that future AISW is even more robust, secure, and safe than our existing POSW.
About the Authors: Ben Zorn is a Partner Researcher at Microsoft Research in Redmond, Washington working in (and previously having managed) the Research in Software Engineering (RiSE) group. His research interests include programming language design and implementation, end-user programing, and empowering individuals with responsible uses of artificial intelligence. Emery Berger is a Professor of Computer Science at the University of Massachusetts Amherst and an Amazon Scholar. His research interests center around building advanced software development tools, and is currently working on harnessing large language models to radically improve these tools, including profilers, debuggers, and compilers.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
