
A version of this blog post will appear as an opinion article in CACM.
Continued progress in the burgeoning field of robotics and autonomous machines depends critically on an efficient computing substrate. For very good reasons, the systems and architecture have largely focused on the software stack of what we dub Autonomy 1.0. This post discusses some of the challenges that Autonomy 1.0 faces, how they might be mitigated/addressed by a new software paradigm, which we dub Autonomy 2.0, and presents some research challenges to the systems and architecture community.
The Need for Scalability
The digital economy has been the primary driver of global economic growth over the past two decades. The Internet industry, a key component of the digital economy, exemplifies this impact. From 2005 to 2010, it accounted for 21% of GDP growth in mature economies. In 2019, the internet industry contributed $2.1 trillion to the U.S. economy—approximately 10% of its annual GDP—making it the fourth largest industry behind only real estate, government, and manufacturing. The Internet industry directly provides nearly 6 million jobs, representing 4% of U.S. employment.
Technological scalability is the cornerstone fueling the continuous growth of the digital economy. The most successful companies in this sector have developed core technology stacks that scale with available computational resources and data, rather than with the size of their engineering teams. WhatsApp serves as a remarkable example: when Facebook acquired it for $19 billion, the company had only 32 engineers serving over 450 million users.
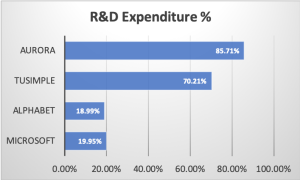
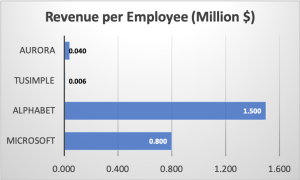
Figure 1: Revenue and Expenditure Comparison: Digital Economy Companies vs. Autonomy Companies.
In stark contrast, today’s autonomous machine technologies, dubbed Autonomy 1.0, embody practices that a scalable industry should avoid. Figure 1 compares the R&D expenditures and revenue per employee of two leading public digital economy companies—Microsoft (representing the software industry) and Alphabet (representing the internet industry)—against two public autonomous driving companies: TuSimple (representing the robot truck industry) and Aurora (representing the robotaxi industry). These autonomous driving companies were selected for the accessibility of their financial data.
Both Alphabet and Microsoft demonstrate remarkable efficiency, allocating less than 20% of their total operating expenditures to R&D. Alphabet, in particular, serves over 4.3 billion users with fewer than 30,000 engineers. Their scalability is primarily constrained by available computational resources and data, rather than by their workforce size.
In comparison, TuSimple and Aurora allocate more than 70% of their operating expenditures to R&D. Autonomous driving companies often face the challenge of re-calibrating their existing technology stacks to adapt to new environments when expanding their user base or deploying services to new regions. Consequently, their scalability is limited by R&D investment or, more directly, by the number of engineers they employ.
This disparity in operational efficiency translates directly to financial performance. Alphabet and Microsoft generate $1.5 million and $0.8 million in revenue per employee respectively, while maintaining high growth rates. Conversely, TuSimple and Aurora generate negligible revenue per employee and struggle with growth. For the autonomy industry to achieve economies of scale comparable to the digital giants, a revolution in the R&D paradigm is imperative.
Autonomy 1.0: An Aging Paradigm
Autonomy 1.0 is characterized by a modular structure, comprising functional modules such as sensing, perception, localization, high-definition maps, prediction, planning, and control. The open-source project Apollo serves as a typical example. These modules often have strong inter-dependencies, so changes to one module not only impact overall system performance but also affect the algorithmic performance of downstream modules. Consequently, the entire system has become complicated and potentially brittle, demanding enormous engineering resources merely to maintain, let alone to advance at a rapid pace.
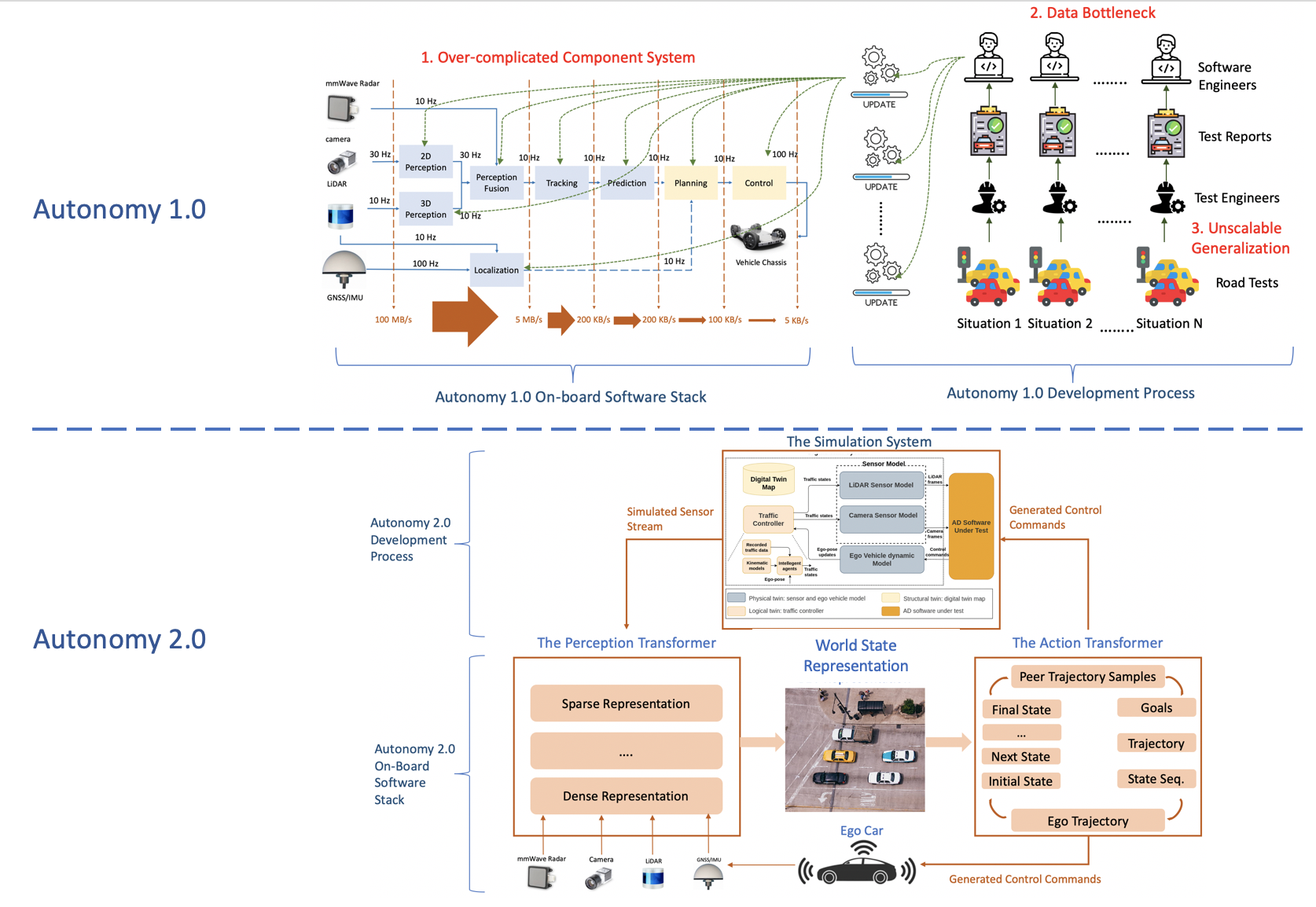
Figure 2: Autonomy 1.0 vs. Autonomy 2.0 Architecture.
We summarize below three major scalability bottlenecks of Autonomy 1.0.
- Complexity Bottleneck: Autonomy 1.0 systems are characterized by intricate designs that demand extensive engineering efforts. These efforts span software and algorithm design, system development, and ongoing maintenance, creating a significant burden on resources and time.
- Human-Data Bottleneck: A critical limitation of Autonomy 1.0 systems is their dependence on fleets of physical vehicles operated by humans for data collection and testing purposes. Additionally, these systems require large-scale data labeling for model training and system evaluation. This approach is not only costly but also presents significant challenges in scaling operations effectively.
- Generalization Bottleneck: The architecture of Autonomy 1.0 systems heavily relies on rule-based processing logic and hand-crafted interfaces. This design philosophy inherently limits the systems’ ability to adapt and generalize to new environments, creating a substantial barrier to widespread deployment and adoption.
How Does Autonomy 2.0 Address These Challenges?
The cornerstone of Autonomy 2.0 is scalability, which is achieved through two crucial ingredients:
- A learning-native software stack that continuously improves with increasing scale of data and computational resources.
- A new paradigm based on digital twins for algorithmic exploration using realistic, controllable, and large-scale simulation before deployment.
A learning-native software stack
How exactly a learning-native software stack for autonomous machines is a wide-open question. There are two general styles. The first is end-to-end architectures, such as vision-language-action models, which use one single deep learning model that turns sensory inputs to actuation commands to the vehicle. An example is DeepMind’s RT-X. An alternative would be a two-component architecture, where perception and action is each implemented by a deep learning model. The argument for the two-component architecture is that it reflects the natural dichotomy between the two. Perception involves observing the environment and inferring its current state based on accumulated observations. It has a single correct answer and permits supervised learning. The Action component builds upon the inferred environmental state and involves decision-making with multiple possibilities, requiring reinforcement learning. These differences necessitate distinct model optimizations and simulation needs.
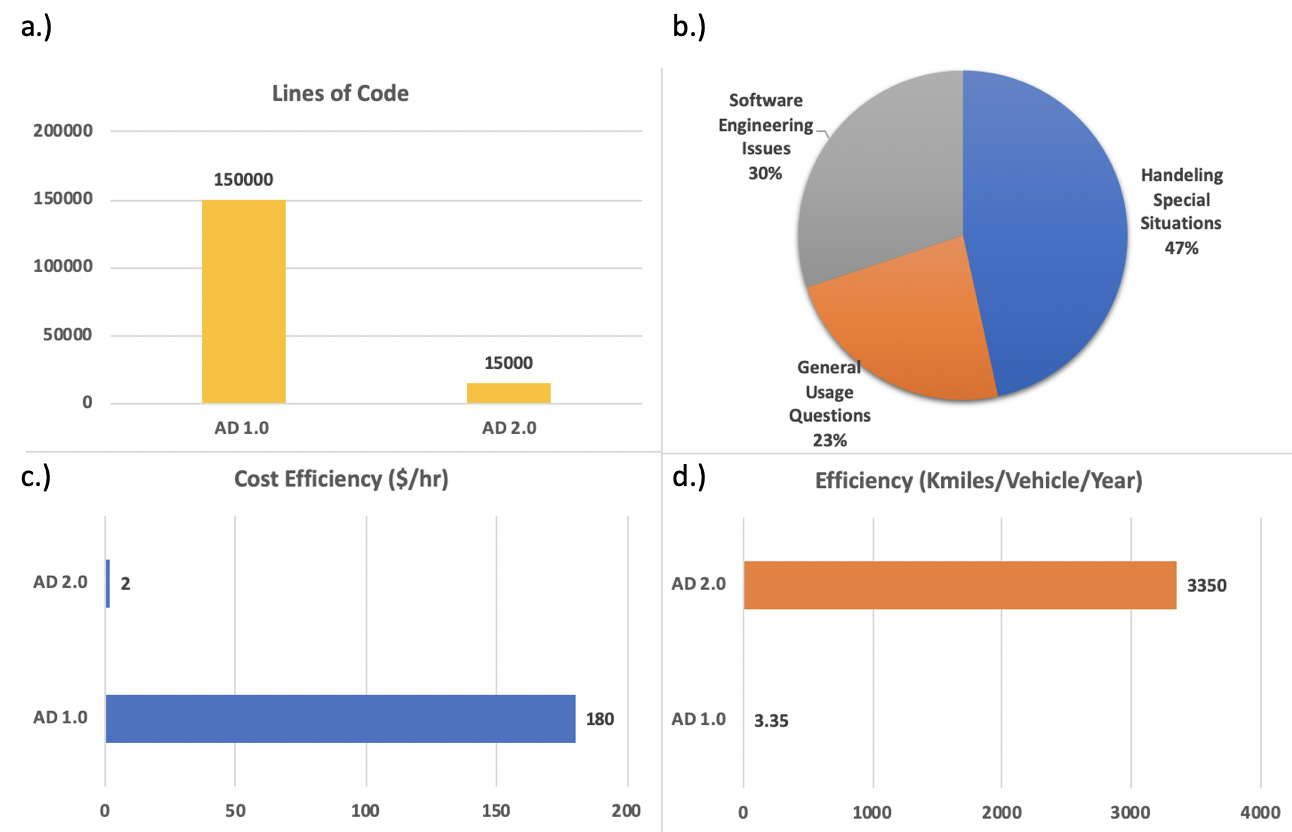
Figure 3: Comparison of Autonomy 1.0 vs. Autonomy 2.0: a.) lines of code in Apollo Perception module (Autonomy 1.0) vs. in BEVFormer (Autonomy 2.0); b.) breakdown of issues in Apollo Planning module; c.) R&D cost efficiency comparisons d.) R&D efficiency comparisons.
We will use the two-component architecture to illustrate the benefit of Autonomy 2.0, which is illustrated in Figure2. It addresses the Complexity Bottleneck by significantly reducing the number of learning-based components and, consequently, the amount of non-learning code that requires maintenance. Figure 3a compares the lines of code in the Apollo Perception module, representing the Autonomy 1.0 approach, with BEVFormer, an example of a perception module in Autonomy 2.0. The Apollo Perception module is ten times larger than BEVFormer, yet BEVFormer has achieved state-of-the-art perception results.
This software architecture also tackles the Generalization Bottleneck present in Autonomy 1.0 by handling corner cases through data-driven model learning instead of hand-crafted logic. In Figure 3b, an analysis of over 400 issues associated with Apollo planning modules reveals that 47% of the issues relate to Apollo failing to handle specific use cases, while 30% are linked to software engineering problems such as interfaces with other modules. In Autonomy 1.0, numerous hand-crafted rules are implemented to handle specific use cases. As these rules accumulate, software quality inevitably becomes an issue.
Simulation Based Development and Deployment
Autonomy 2.0 address this Human-Data Bottleneck through an emerging technology known as digital twins, with two key insights:
- An efficient and sophisticated data “engine” is essential for processing and mining rare and critical driving scenarios from large-scale real-world data. Such data is invaluable for improving system performance.
- Neural simulators trained with real-world data can be the source of almost unlimited, realistic, scalable and highly controllable driving scenario data for extensive system evaluation and model training, both for environment perception and action planning.
The development and testing of autonomous driving software using synthesized virtual scenarios offers significant advantages over the physical-only approach of Autonomy 1.0. This method accelerates the evaluation process by a factor of 10^3 to 10^5 and reduces testing costs by two orders of magnitude. Figure 3c illustrates the dramatic improvement in R&D cost efficiency, a 90-fold reduction in costs. Figure 4d demonstrates a 1000-fold increase in R&D efficiency measured as kmiles/vehicle/year. The combined effect of these improvements results in a potential 10^5-fold enhancement in overall efficiency under the same engineering investment in Autonomy 2.0. This paradigm shift effectively eliminates the human-data bottleneck, as scalability becomes primarily constrained by available computational resources rather than the number of engineers.
Challenges and Opportunities
Systems and Architectural Support: While a great deal of prior work in systems and architecture, for very good reasons, has focused on accelerating Autonomy 1.0 software stacks, the rise of Autonomy 2.0 merits attention from our community. How do we go about thinking about systems and architecture support when the software stack is in a state of constant flux — being explored, revamped, and occasionally overhauled? What abstractions, both in software and hardware, can we explore to navigate this challenge? It’s likely that conventional hardware primitives for (sparse/dense) linear algebra, point cloud processing, and stencil operations would not go away even in Autonomy 2.0, so from the hardware perspective is there really anything new?
System Inspection and Debuggability: To maintain engineering productivity and product quality, appropriate data infrastructure, development tools, and a comprehensive set of evaluation metrics are required but currently under-developed. This would involve creating automated workflows and tools that streamline the development process, manage the complexities of AI-driven software, and ensure reliable performance through rigorous testing and validation. The goal is to enhance productivity, reduce errors, and accelerate the time-to-market for autonomous systems.
About the authors:
Yuhao Zhu is an Associate Professor of Computer Science and Brain and Cognitive Sciences at University of Rochester.
Shuang Wu is a Principal Scientist at Nvidia focusing on autonomous driving technologies.
Bo Yu is a researcher at Shenzhen Institute of Artificial Intelligence and Robotics for Society, Shenzhen, China.
Shaoshan Liu is a director of Embodied Artificial Intelligence at Shenzhen Institute of Artificial Intelligence and Robotics for Society, Shenzhen, China.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
