
Introduction
Memory systems are evolving into heterogeneous and composable architectures. Heterogeneous and Composable Memory (HCM) offers a feasible solution for terabyte- or petabyte-scale systems, addressing the performance and efficiency demands of emerging big-data applications. However, building and utilizing HCM presents challenges, including interconnecting various memory technologies (e.g., using Compute Express Link or CXL), organizing memory components for optimal performance, adapting system software traditionally designed for homogeneous memory systems, and developing memory abstractions and programming constructs for HCM management. To understand the current status, needs, and challenges in HCM, the first workshop for Heterogeneous and Composable Memory was held with HPCA’23 on Feb 26, 2023. This article lays out the ideas and discussions shared at the workshop.
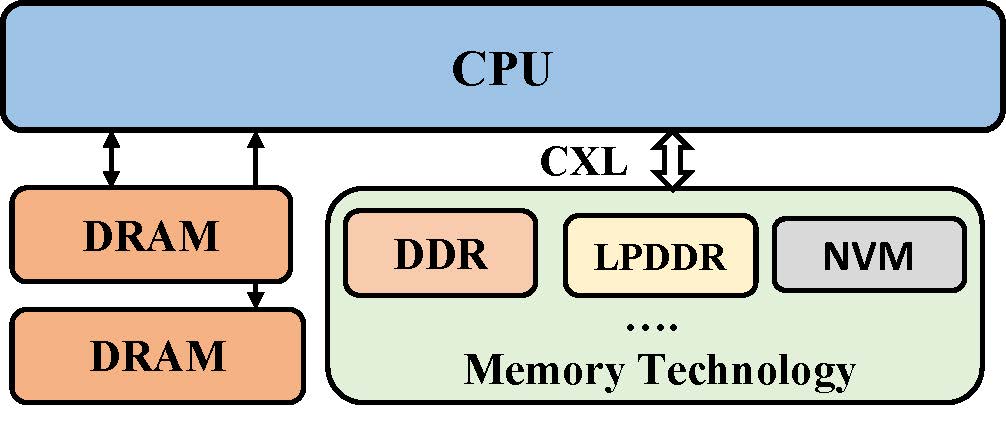
Figure 1: Heterogeneous memory with CXL (source: Maruf et al., ASPLOS’23)
Current status, use cases, and needs
In the keynote speech, Irina Calciu (co-founder of Graft) explored the potential of heterogeneous and disaggregated memory in modern applications (ASPLOS’21). Memory disaggregation separates memory pools from traditional server boxes, enabling more flexible resource allocation and potentially reducing costs. There are three common mechanisms to access remote memory: modifying applications, modifying virtual memory, and hardware-level cache coherence support. A combination of these mechanisms may be necessary to tackle challenges arising from heterogeneous memory systems and NUMA architectures. Such a combination requires new abstractions and programming models for effective management. Calciu projected multiple use cases of CXL-based memory systems, such as in-place data transformation, encryption, checkpointing, replication, near-memory computing, and detection of illegal data access patterns.
Daniel S. Berger (Microsoft) shared the state of memory systems in the public cloud and projected two use cases of CXL-based disaggregated memories in the cloud (IEEE Micro and ASPLOS’23). The state of cloud memory systems can be characterized as 1) there are no page faults as memories are mostly statically pinned, 2) as memories are increasingly stranded, more memory might not lead to performance improvement due to CPU core saturation, 3) customers tend to overprovision memory (45% memory are untouched on average), 4) it is extremely latency sensitive; bandwidth is not a problem in the cloud. CXL-based disaggregated memory provides a new opportunity with two orders of magnitude better performance than RDMA (as illustrated in Figure 2). The recently announced CXL3.0 even lowered the latency by introducing a multi-headed device that collapses switches and memory controllers. Given this state, Daniel projected two use cases of CXL technology in the public cloud; 1) reusing decommissioned DDR4 in DDR5 servers (CXL 1.1) and 2) creating a flexible DRAM pool shared across hosts for peak usage (CXL 2 or 3).
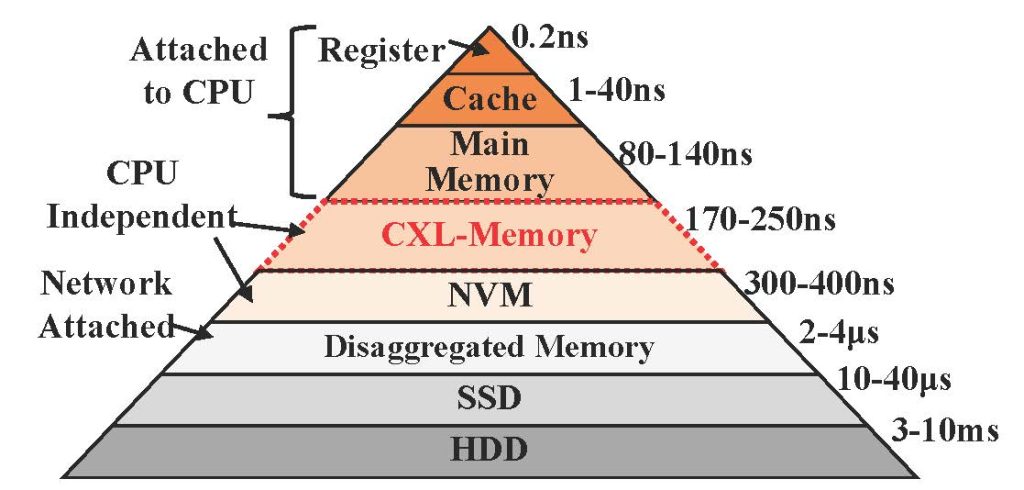
Figure 2: Latency characteristics of memory technologies (source: Maruf et al., ASPLOS’23)
Junhyeok Jang presented a collaborative study between KAIST and Panmnesia, which showcased another application of CXL technology in enhancing the robustness of recommendation model training (IEEE MICRO). In large recommendation models, failure tolerance is important to continue training upon failures but checkpointing may cause performance degradation. By leveraging CXL-based cache coherent communication, they introduce a platform with a CXL-GPU and multiple CXL-mem persistent memory devices that enable checkpointing to be done in the background by leveraging the statically determined batch shape information of the target recommendation model.
Jason Lowe-Power (UC Davis) discussed smart memory management and the need for an efficient interface for it. He emphasized the importance and necessity of supporting various application semantic differences with large and heterogeneous memory systems. By sharing the effectiveness of profile-guided optimization for tensor allocation and movement between DRAM and NVDIMMs (ASPLOS’20), he projected that the heterogeneous memory systems need a combination of a high-level data management interface (DMI) and a low-level DMI for efficient data block management.
Hasan Al Maruf (Univerity of Michigan) introduced a Linux interface to smartly manage CXL-based tiered memory systems (ASPLOS’23). In the heterogeneous tiered memory system, the memory management should include lightweight demotion to the slow memory tier, efficient hot page promotion to the fast memory tier, optimized page allocation path to reduce latency, and workload-aware page allocation policy. Under these goals, Hasan and his collaborators propose to proactively identify inactive pages and maintain them in a separate demotion pool, allowing migration to remote nodes when local memory is insufficient. To reduce unnecessary demotions of the promoted pages, they consider active LRU heuristics before promoting pages from slow to fast memory.
Christina Giannoula (University of Toronto) introduced architectural support for efficient data movement in fully disaggregated systems (ACM Measurement and Analysis of Computing Systems). The proposed solution minimizes data transfer cost through a selective data movement granularity (cache lines, pages, or both) by monitoring inflight sub-block and page buffers, page compression, and critical cache line prioritization.
Research challenges
Various research challenges were discussed in a panel, Jason Lowe-Power (UC Davis), Daniel S. Berger (Microsoft), Michele Gazzetti (IBM), Manoj Wadekar (Meta), Debendra Das Sharma (Intel), and Hasan Al Maruf (University of Michigan).
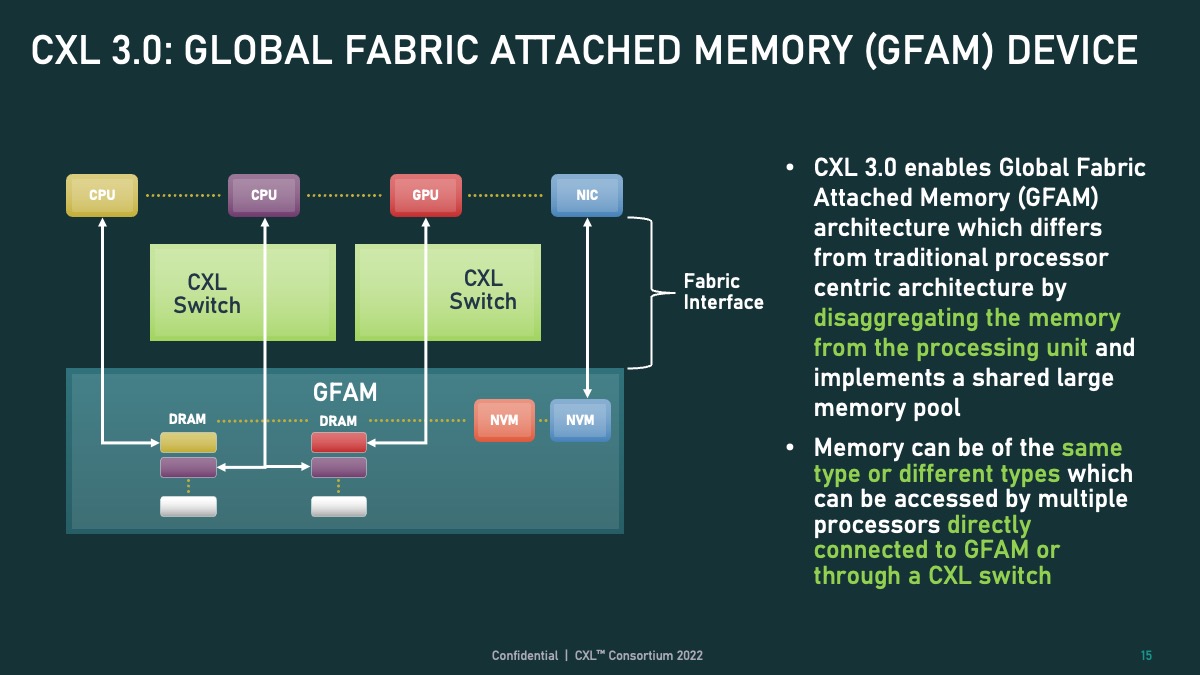
Figure 3: A shared large memory pool via CXL 3.0 (source: CXL Consortium)
About different stages of memory disaggregation (especially CXL memory-based memory disaggregation). CXL-based memory may appear in the production environment, following several stages: The first stage may appear as a memory expander, and the second stage may appear as memory pooling (e.g., GFAM in Figure 3). The first stage is expected to be deployed within one to two years, while the second stage, even at a small scale, may take about five years. No matter what stage the memory disaggregation is at, There are multiple commonalities.
- The cost and power are the major drivers behind it. The use cases will be prioritized based on which use cases can get the most benefit out of memory disaggregation.
- The memory bandwidth will be a key player because the traditional method to add memory bandwidth by adding memory channels is not scalable. The far memory will provide a memory bandwidth tier (not only a memory capacity tier).
About application transparency. The application adoption of CXL memory (or other memory disaggregation solution) will go through multiple phases. In the first phase, CXL memory should be transparent to applications without requiring changes, especially in public cloud environments. As CXL memory becomes more common, new programming models or disruptive changes may be accepted. Also, we cannot expect the programmer to know data placement and handle different memory latency and bandwidth in heterogeneous memory. But It may be reasonable to allow the programmer to pass the application semantics (coming all the way from the application level down to the CXL mechanism). Currently, being application-transparent has a higher priority.
About CXL hardware availability with academia. The industry may provide some FPGA-based simulation platforms. Using emulation (e.g. NUMA-based) can also work. Also, besides the hardware, we see the software ecosystem starts to appear (e.g., Meta TPP).
Summary
All the talks and discussions have a common agreement that disaggregated and heterogeneous memory systems can provide better resource utilization, resource scaling, and fault tolerance. To maximize performance benefits, a thorough understanding of individual data objects (e.g., hot or cold data, access orders, granularities, latency-bound or bandwidth-bound, and lifetime) and the design of interfaces that leverage semantic information for memory management are critical. Therefore, software-hardware co-design is an essential component. But, before anything else, the most urgent hurdle seems to be the limited commercialized platforms and simulators for idea verification and killer application development.
About the Authors:
Hyeran Jeon is an Assistant Professor at the University of California, Merced. She leads the Merced Computer Architecture Lab for energy-efficient, reliable, and secure computer architecture and systems research.
Dong Li is an Associate Professor at the University of California, Merced. He is the director of the Parallel System Lab at Merced and was a research scientist at the Oak Ridge National Laboratory (ORNL). His research focuses on system support for memory heterogeneity.
Jie Ren is an Assistant Professor of Computer Science at the College of William & Mary. Her research aims to improve the performance and resource efficiency of heterogeneous memory systems.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
