
We live in the era of machine learning. As Geoff Hinton and Yann LeCun emphasized in their recent Turing lecture, the rise of machine learning (ML) was in great part facilitated by cheap and easy to use high-performance computing that has allowed ML models to be trained using more data and with deeper networks than in the past. As such, it is no surprise that computer architects have mobilized to support machine learning. Over the past three years, more than 65 papers were published in top computer architecture conferences focused on architectural support for machine learning. Dozens of hardware startups are actively pursuing new solutions, and even internet service companies have internal hardware efforts to enable high-performance and efficient training and inference through high-performance CPUs, GPUs, FPGAs, and accelerators (Microsoft Brainwave, Google TPU, Facebook Zion/Kings Canyon, Amazon Inferentia).
Since the dawn of computing, humanity has been fascinated by the possibility that machines may equal or surpass humans on tasks associated with intelligence (Bush 1945, Von Neumann 1945, Turing 1950). Human nature dictates that we are most drawn to machine learning models that emulate human capabilities such as computer vision and natural language processing. Such models have unique characteristics that provide an excellent playground for architecture research. Vision tasks tend to be well-suited to convolutional neural networks (CNNs) and as such have excellent locality that can be exploited in many creative ways. On the other hand, natural-language processing (NLP) tasks tend to best tackled by recurrent neural networks (RNNs) and sequence-to-sequence “transformer” style networks that require an entirely different set of optimizations.
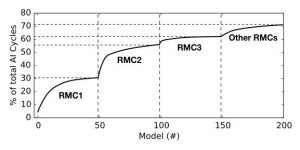
Figure 1: A majority of AI inference cycles are spent on DNN-based personalized recommendation systems.
In this blog post, we would like to draw the attention of the research community to another important class of neural networks, personalized recommendation systems. Recommendation systems form the backbone of most internet services: search engines use recommendation to order results, social networks to suggest friends and content, shopping websites to suggest purchases, and video streaming services to recommend movies [Facebook, Google, Alibaba, YouTube]. Recent publications hint at the scale of compute required to support recommendation systems. For example, an HPCA’18 paper from Hazelwood et al. suggests that an important class of Facebook’s recommendation use cases require more than 10x the datacenter inference capacity compared to common computer vision and NLP tasks. Figure 1 shows that a few major categories of recommendation models (i.e., RMC1, RMC2, RMC3, other RMCs) account for over 72% of all AI inference cycles in Facebook’s production datacenter. Following this, an arXiv paper from Gupta et al. analyzes and highlights the system architecture and infrastructure challenges faced by neural recommendation inference use cases (to appear at HPCA-2020).
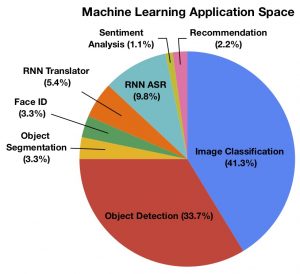
Figure 2: The breakdown of application spaces of ML related papers published in HPCA, ASPLOS, ISCA, and MICRO over the last five years.
Unfortunately, this stark difference in compute requirements appears to have not been reflected in the amount of research attention drawn to recommendation systems. Figure 2 shows the application distribution of papers published in the top four computer architecture conferences over the last 5 years.
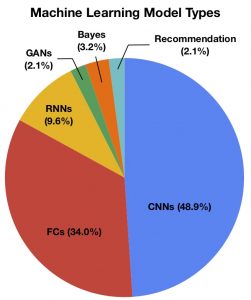
Figure 3: Among the papers analyzed in Figure 2, the vast majority (over 90%) is focused on CNN, FC, and RNN model types.
The model types used in the papers often focused on CNN and RNNs (Figure 3). None of the papers have explicitly tailored the design and optimization for recommendation systems. We believe this is because, at least in part, recommendation system models require large and proprietary datasets to train effectively. In contrast, the CV and NLP communities have developed effective datasets like ImageNet and LibriSpeech. As such, recommendation systems tend to be less well-understood by academics, companies that do not have access to these datasets, and the broader research community. Paper analysis shown here is conducted by Udit Gupta, Lillian Pentecost, and Ted Pyne.
Personalized recommendation systems
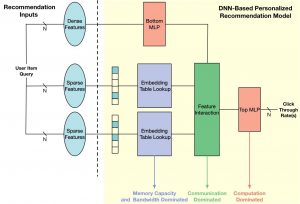
Figure 4 depicts the generalized architecture of a DNN-based recommendation system.
Personalized recommendation is the task of recommending content to users based on continuous (dense) and categorical (sparse) features. The use of categorical data to describe higher-level attributes is a unique aspect of highly accurate, DNN-based recommendation systems. The categorical features are often processed using embeddings while continuous features are processed with a bottom multilayer perceptron (MLP). Then, interactions of different features are considered before the results are processed with a top MLP and fed into a sigmoid function to produce the probability of a click (i.e., click through rate). The click through rate is then used as a parameter to evaluate the quality of the recommendation inference. Figure 4 depicts the generalized architecture for a DNN-based recommendation system, used in recent literature (Alibaba, Facebook, Google).
Like convolutional and recurrent approaches, personalized recommendation also has unique performance characteristics. The architecture is composed of compute-dominated MLPs as well as memory capacity limited embeddings. It is therefore natural to rely on data-level parallelism to improve the performance of MLPs/FCs and model parallelism to address the memory capacity requirement of embeddings.
Compared to the Fully-Connected (FC), CNN (often found in image classification and object detection), and RNN layers (often found in automatic speech recognition and natural language processing), embedding table operations in the DNN-based recommendation systems exhibit significantly lower compute density as well as poor spatial and temporal locality at the cache hierarchy, imposing significant stress on existing off-chip memory bandwidth. Across the different layers for unique use cases, resource requirements are drastically different.
When examining representative at-scale recommendation inference running on a state-of-the-art server-class processor, there is not a single, dominating kernel function as an obvious acceleration candidate. Even when composed based on the same generalized architecture, the performance bottleneck varies from one recommendation system (with FC dominating the end-to-end execution time) to another (embedding table operations).
In order to enable algorithmic experimentation and benchmarking, Facebook recently released an advanced Deep Learning Recommendation Model (DLRM). We hope that it will help enable and accelerate innovation for neural recommendation systems modeling and co-design.
Looking Ahead
Current publicly-available benchmarks for DNNs focus on neural networks with FC, CNN, and RNN layers. The benchmarks have enabled the computer architecture and system community to make significant strides in optimizing the performance, energy efficiency, and memory footprints of convolutional and recurrent neural networks. The results span from algorithmic innovations to the use of reduced precision variables, and from system-level techniques to the design and deployment of accelerators. These solutions primarily target convolutional and recurrent approaches. Thus, the benefits from these optimization techniques often does not directly translates onto DNN-based recommendation models as the core compute patterns of the models are intrinsically different, introducing unique memory and computational challenges.
In this blog post, we present the open issues and challenges often faced by information retrieval community with early finding and summary of directions that we hope to inspire architecture research and a broader set of solutions to optimize end-to-end personalized recommendation systems:
- Optimizing recommendation translates to large capacity saving: DNN-based personalized recommendation lays an important foundation for many machine learning-powered ranking problems in industries. However, it is less well understood and studied while presenting ample room for optimization.
- Memory system optimization is the key: For an important subset of personalized recommendation, memory capacity and off-chip memory bandwidth is the primary performance limiting factor.
- One size does not fit all: As we build accelerators for this important class of recommendation workloads, we have to be mindful about the balance between flexibility and acceleration efficiency.
- Full system stack designs enable efficient yet flexible acceleration: Programmability is a critical, but often an overlooked aspect of high performance and efficiency delivery in accelerator-enabled systems. As more and more acceleration logics are making their way into datacenter at scale, being able to program these accelerators to extract the promised theoretical peak TFLOP performance requires a meticulously designed software stack.
Acknowledgement
The work described in this blog post is built by a large team of colleagues across Facebook and would not have been possible without the time and contribution from many colleagues at Facebook: Xiaodong Wang, Brandon Reagen, Bradford Cottel, Bill Jia, Andrey Malevich, Mikhail Smelyanskiy, Liang Xiong, and Xuan Zhang. The authors would especially like to thank Facebook Research Scientists Maxim Naumov and Dheevatsa Mudigere for the collaboration on the Deep Learning Recommendation Model benchmark, its analysis and optimization, as well as their feedback on this blog post.
About the Authors: Wu, Lee, and Hazelwood are with Facebook’s AI Infrastructure Research team, which focuses on next-generation systems for large-scale machine learning workloads. Gupta and Brooks are with Harvard University and collaborate with Facebook.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
