
Introduction
Computer graphics exemplifies hardware-software co-design. Since its inception, rendering algorithms have been developed hand in hand with hardware architecture. Graphics is only becoming more important with the rise of new visual applications such as Virtual/Augmented Reality and digital twin, as well as the increasing desire for creative expression and visualization.
In this two-part post series, I will introduce some of the fundamental ideas and recent advances in graphics rendering, and argue why the stage is set for architects to contribute. Part I will focus on ray tracing, and Part II will focus on the confluence of AI and rendering.
The Gist of Physically-based Rendering
While conventional rendering algorithms are based on rasterization, an increasing amount of research is focused on physically-based rendering (PBR). PBR delivers far superior photorealism because it is physically correct. At its core, PBR uses laws of physics to simulate light transport in space. As a reasonable simplification, we model light as rays; thus, ray tracing is the natural choice to simulate light transport.
The basic idea of ray tracing is incredibly simple: cast a ray from the eye/camera through each pixel to the scene, and ask two questions: 1) visibility: does the ray intersect with the scene, and 2) shading: if so, what’s the color of the intersection point along the ray? In practice, the second step calculates the spectral radiance (stated informally, radiance is the power of a ray), from which the color can be derived based on basic color science.
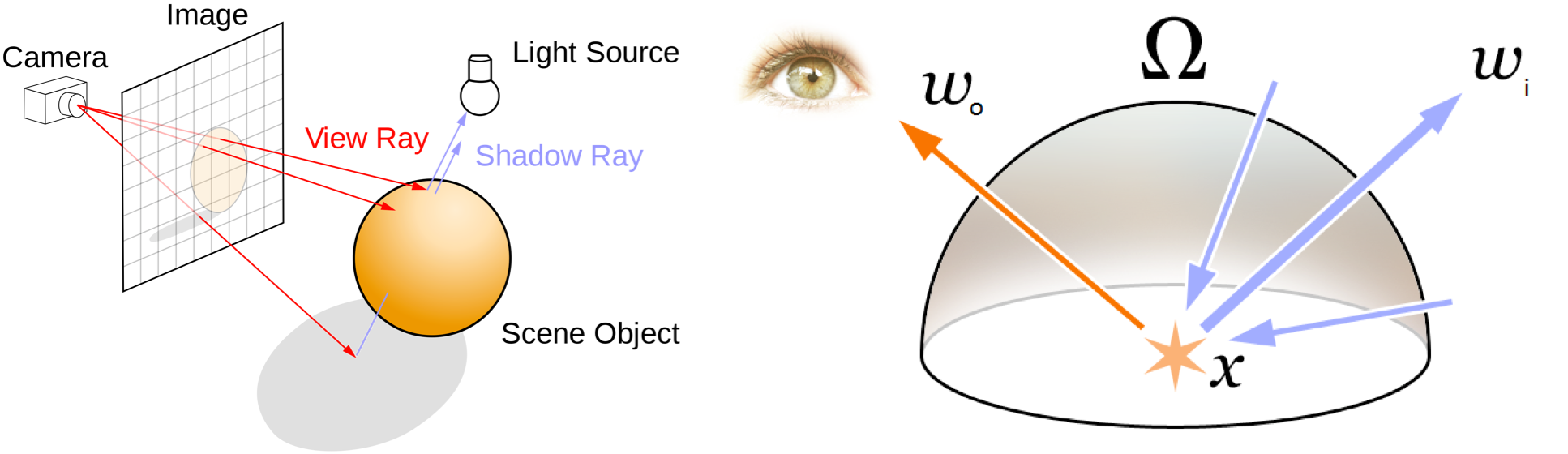
Figure 1: The two key issues in physically-based rendering. (left) The visibility problem is addressed through casting rays and performing ray-scene intersection tests (source). (right) The shading problem is formulated elegantly in the rendering equation (source).
While the visibility problem is at least conceptually easy, shading is not. Arguably one of the most significant developments in graphics was the introduction of the rendering equation, which formulates an elegant and physically rigorous way for shading: the radiance of an outgoing ray from a surface point is a function of the radiances of all the incoming rays incident on the same point:
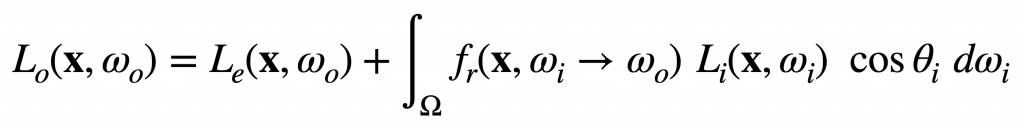
Without going into too much detail, we can make two observations of this equation, both of which impact on the algorithm and hardware design.
First, calculating light transport is recursive — the radiance L appears on both sides of the equation. Intuitively, the outgoing radiance of a ray (Lo) depends on the radiance of the incoming rays (Li), which can be calculated by recursively applying the rendering equation. Critically, this recursion means that the visibility problem will have to be solved for each shading recursion, leading to a massive amount of ray-scene intersection tests. In fact, the overall rendering time is almost completely dominated by the ray-scene intersection test.
Second, the integration is almost impossible to solve analytically in practice, since there is no analytical form of the integrand for general scenes. Therefore, this integration is solved using Monte Carlo methods, which, critically, are sampling based. Naturally, high-quality rendering requires sampling a lot of rays. Offline rendering (e.g., movies) usually samples a pixel with thousands of rays, whereas in real-time rendering (e.g., games/VR) the budget is only about 0.25 to 4 samples per pixel1 This number obviously is a moving target and will likely slightly increase as the hardware gets better. But it’s believed that we won’t get to sample more than 10-20 rays per pixel.. Taking fewer rays improves the rendering speed, but also leads to low rendering quality, e.g., aliasing, noise, lower resolution, etc.
Hardware Support for Ray Tracing
Ray-scene intersection is the single most important target for performance optimization. A common algorithmic optimization is to use “acceleration structures” (not to be confused with hardware accelerators!), such as the KD tree and Bounding Volume Hierarchy (BVH), that partition the space/objects in the scene to prune the search space. Today, all ray tracing accelerators provide some sort of dedicated hardware for ray-scene intersection, mostly based on BVH. The prime example is the RT cores in Nvidia’s recent Turing architecture, where dedicated ray-primitive intersection hardware sits alongside conventional CUDA cores. It is the dedicated intersection hardware that makes it possible to even talk about interactive ray tracing, which historically is limited to off-line uses.
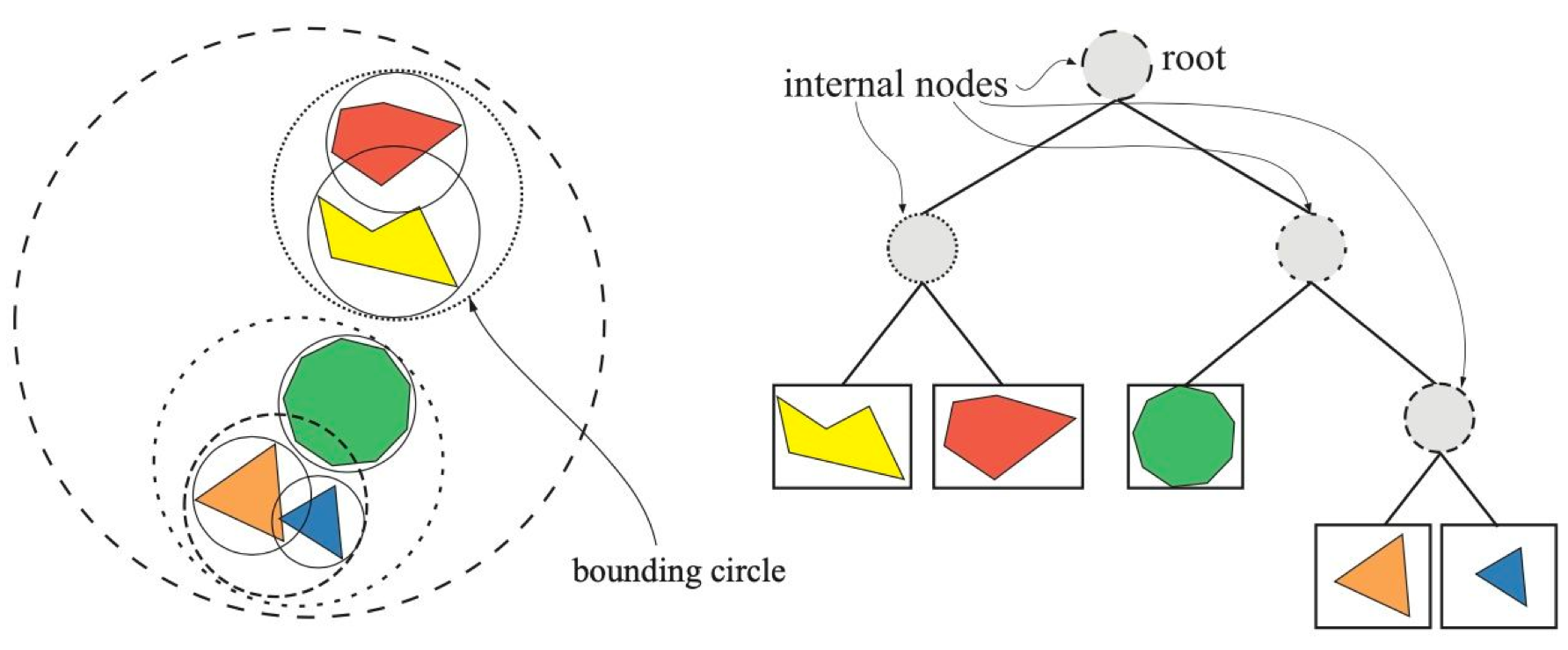
Figure 2: Illustration of BVH (source: Real-Time Rendering, 4th Edition). Primitives in the scene are represented by their bounding volumes, which are hierarchically organized as a tree. A ray-scene intersection test traverses this tree; if a ray doesn’t intersect a node’s bounds, the entire subtree beneath that node can be skipped.
The central challenge in hardware ray tracing is the usual suspect: irregular memory accesses, which, in this case, stem from the rather arbitrary distributions of the rays and the scene geometry. This is especially a problem when the data can’t fit in the on-chip SRAM, e.g., when the scene is complex and/or a large amount of rays are traced (for high rendering quality). A recent study on a dedicated ray tracing accelerator shows that, when rendering a reasonably complex scene with 10.5 million triangles, over 80% of the rendering time is spent on memory stalls and the DRAM energy contributes to over 80% of total energy.
To address the memory inefficiencies, an idea that has been extensively explored is to schedule rays to maximize locality, e.g., bundling rays with similar locality characteristics. A recent work pushes this idea to extremes by exposing completely streaming memory accesses: instead of tracing a ray to its completion while loading (irregular) scene data, stream the scene data and operate on all the rays that intersect with the portion of the scene that’s on-chip. This is reminiscent of the classic streaming architecture.
What Do All These Mean for Architects?
Efficient PBR Hardware. To date, hardware support for PBR has primarily focused on accelerating ray tracing, which will continue to be important, although we might have to get even more creative as the graceful technology scaling comes to an end.
The need for efficient PBR will be accelerated by cloud graphics. A lot of the graphics computations are already taking place in the cloud, mostly for cloud gaming; this trend will continue, enabled by continuing improvements in communication technologies and driven by new applications such as cloud VR and digital twin. The economics of the cloud will most likely favor special hardware for markets where the return on investment is high, which the graphics market certainly is. Efficient cloud GPU design for future rendering is perhaps the next billion-dollar challenge.
General-Purpose Irregular Processor? We should, however, be wary of overly specializing the hardware. The success of GPGPU shows just how powerful graphics processors can be when they are programmable. Interestingly, if we see current rasterization-based GPUs as general-purpose accelerators for regular applications as they certainly are now, could future ray tracing-based GPUs be used as general-purpose irregular accelerators? For starters, ray-object intersection is fundamentally a tree traversal problem, which shows up in many irregular applications beyond graphics.
Using ray-tracing hardware for general-purpose irregular computing beyond ray tracing requires two components to come together: hardware and programming model. Hardware-wise, how/if should we build a microarchitecture that is super efficient for ray tracing but is reasonably efficient for general irregular kernels? The RT cores in Nvidia’s Turing GPUs perform a very specific form of tree traversal where the branching logic is specific to bounded intersection checking, which is not easily extensible to more generic traversals — unless the traversal hardware is made more generic.
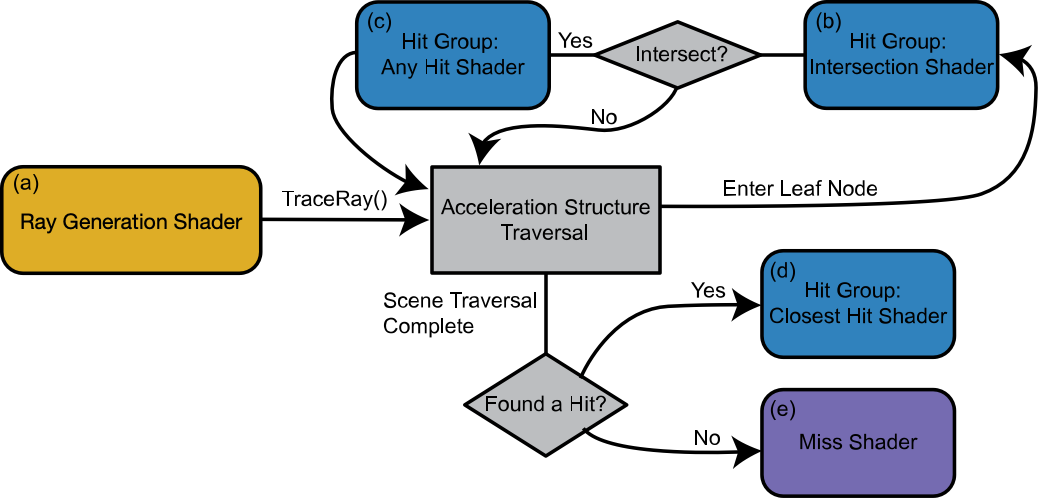
Figure 3: The rendering pipeline of OptiX (adapted from here). It’s a fixed organization with programmable stages. Conventional rasterization programmers should be quite familiar with this strategy, except the overall pipeline is designed for ray tracing rather than rasterization and, therefore, the user-defined programs carry different functionalities.
Perhaps the more interesting and difficult problem is the programming model, which will have to play a key role, just like how CUDA enables GPGPU in its current form. Common graphics APIs such as Vulkan and DirectX have support for ray tracing; there are also dedicated ray tracing programming models such as OptiX. All these efforts, however, do not have general-purpose programmability (for irregular applications) as the main design goal, leaving much on the table.
Figure 2 shows the programming model of OptiX. It defines a fixed pipeline organization, but also exposes interfaces for user-defined programs (a.k.a., shaders in the parlance of the rasterization pipeline) to control different stages of the rendering pipeline. It is these programmable shaders that provide the opportunity for implementing algorithms beyond ray tracing. Recent papers have started leveraging ray-tracing hardware for algorithms beyond ray tracing, and have shown significant speed-ups over conventional GPU implementations (e.g., CUDA).
However, programmers still have to constantly think about rays and geometry; essentially they have to manually reformulate the algorithm of interest as a ray tracing problem. In comparison, today’s GPGPU programmers do not think about pixels and triangles at all. It would be interesting to explore a programming interface that abstracts the details of ray tracing away.
Tightly connected to the programming model issue is the design of the run-time system, of which the ray scheduler is one of the most important components as mentioned earlier. Today, the scheduler is internal to the OptiX run-time system and hyper-optimized for ray tracing. One could imagine that the optimal scheduler could depend on the specific algorithm being executed. Therefore, it would be interesting to explore how the programming model could allow user-defined schedulers (and run-time policies in general), perhaps decoupled from the main algorithm itself in a Halide style.
Acknowledgements: Thanks to John Owens, Peter Shirley, and Adam Marrs for comments and discussions. Any errors that remain are my sole responsibility.
About the Author: Yuhao Zhu is an Assistant Professor of Computer Science at University of Rochester. His research group focuses on applications and systems for visual computing.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
- 1This number obviously is a moving target and will likely slightly increase as the hardware gets better. But it’s believed that we won’t get to sample more than 10-20 rays per pixel.
