
Brain-computer interfaces (BCIs) connect the brain with computers and machines, forging a link between natural intelligence and artificial intelligence (AI). In doing so, they enable the use of computational platforms to treat debilitating neurological diseases like epilepsy or Parkinson’s, restore brain function lost due to disease or injury, and even augment human cognition to transcend the current limitations of natural intelligence. BCIs also make it possible for humans one day to leverage the power of AI and process the vast information across the entire internet, with only their thoughts – just like an infinite brain.1The term is a reference to The Infinite Brain (1930), one of the first works of fiction that described a device that can read the brain’s electrical activity and enables uploading the brain’s memories and intelligence into machines.
In an earlier blog post, we highlighted how computer architects can help inform the design of emerging BCIs. In the current article, we present why computer architects stand to benefit by targeting BCI design, and provide an overview of state-of-the-art BCIs, including the HALO [1] and SCALO systems [2] that we have designed.
What’s in for the Computer Architect?
BCIs present some of the most extreme constraints to design for, which conventional computer architectures cannot meet adequately, forcing architects to innovate. This has been our experience as well. In fact, such virtuous forces of innovation between architectures and applications is reminiscent of what happened at the early days of computing.
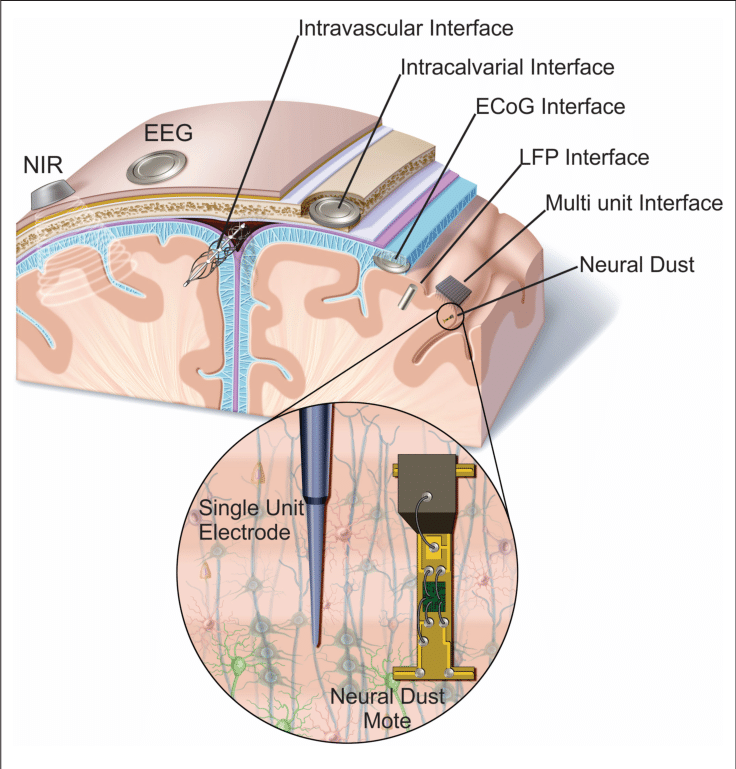
Different modalities of sensing neural activity in the brain, shown with a cross-section of the skull and the brain. The topmost layer is the scalp. Near Infrared (NIR) and electroencephalography (EEG) are wearable methods while the others including electrocorticography (ECoG) and local field potential (LFP) interfaces require surgery. Picture credit: [3].
Throughput: Roughly, there is about a few terabits per second (Tbps) of neural activity across the trillions of synapses in the brain [4] that an ideal BCI should process. Moreover, such processing must read data across timescales ranging from the microseconds to seconds and longer following the multi-timescale processing in the brain. For reference, a UHD video stream uses a few tens of Mbps.
Latency: For BCIs to be effective, real-time response is a necessity. The timescale of response varies depending on how the BCI is used. In research studies, e.g., with animals to understand which neural circuits are involved in a particular task, BCIs must offer closed-loop function (i.e., sense-process-stimulate) within a few microseconds. Several disease treatment applications, both clinical and research, require response times of a few milliseconds.
Power and Thermals: It is widely accepted that the temperature of the brain tissue should not rise beyond 1 C to avoid damage. The safe power under this limit varies from a few microwatts to a few milliwatts depending on the specific location of the implant. Finite element studies (e.g., [5]) have shown that regions with higher blood flow and cerebrospinal fluid (CSF) can actively dissipating heat allowing the use of a few milliwatts of power. Regions closer to the skull where such dissipation is lacking, are restricted to lower levels of power consumption.
Power and thermals also restrict BCI communication data rates. Wired connections between implants for distributed processing, or between implants and external servers for offloading data or compute, do not consume power but pose risk of infection. The latter wires tether users, restricting their movement. The alternative is to use wireless radios, but at the W to mW range suitable for implantation, these offer low data rates (a few Mbps) or work at shorter distances or support one-way communication only, e.g., from the BCI to external servers.
On-device Distributed Processing: Being able to read and modulate as many brain regions and neurons as possible is crucial for BCIs to be effective. This is because brain function, or dysfunction, arises from interactions between multiple regions, and across different timescales. Many emerging BCI applications are now network applications that simultaneously process data from multiple regions.
Supporting network neuroscience applications with BCIs obviously requires using many distributed neural sensors and stimulators. However, processing the data from these increasing number of neural streams is a challenge. One approach is to centralize processing on a single processor that acts as a hub, but the power and thermal constraints of implantation severely limit the data that can be processed in one location. Another alternative is to offload processing entirely, which is what most devices today choose. Unfortunately, the same power and thermal constraints also restrict the communication data rates of implanted BCIs, and offloading processing results in unacceptable latencies. Instead, the preferred approach is to distribute computing capabilities, keeping them close to the sensors/stimulators for real-time performance, and allowing neural data processing to scale.
Processing Capabilities: BCI applications use complex signal processing algorithms to decode or stimulate neural activity. Examples of such algorithms include signal similarity measures (e.g., dynamic time warping or DTW), correlation functions, spectral and component analyses (e.g., fast Fourier transform or FFT, principal component analysis or PCA), clustering, classification methods (e.g., support vector machines or SVMs), and neural network or machine learning (ML)-based signal processing.
The specific methods that the hardware must support depend on the application being targeted, but a more general-purpose functionality is highly desirable for a couple of reasons, which we have also described in our earlier post. One, it helps the BCI to adapt to changing brain function and electrode sensitivity which occur commonly. Second, it enables research into new neural-decoding algorithms. Implanting a new device for each algorithm or its variant is impractical either in humans or animals. Since our previous post, we have encountered additional reasons why flexibility is important. One such reason is that, typically, BCIs receive research or clinical approval for treating specific diseases. However, after implantation, the same device is often used for multiple purposes since the risks and cost of implantation is high, or because individuals are likely to develop other neurological conditions. For example, a BCI implanted in a patient at BrainGate to provide motor function [6] is also being used to study speech decoding, which was not envisioned at the time of the implantation.
Designing BCIs to meet these stringent constraints is hard. It perhaps cannot happen with innovation at just a single layer of the computing stack. Instead, BCI design requires cutting across layers and using aggressive co-design. This is also the approach we’ve taken. Next, we review a few state-of-art BCIs including ours, in how they approach the BCI design problem.
State-of-the-Art BCIs
BCI designers have adopted various design strategies to meet the challenging constraints, and existing BCIs are an outcome of those choices. Table 1 compares state-of-the-art BCIs. Commercially available BCIs approved for research or clinical purposes (e.g., Medtronic, Neuropace) have opted to limit their functionality to meet the power and thermal constraints. They focus on a single function, offer little to no on-device compute, or interface with a single region, or reduce the neural data rates they can process. The Neuralink design under development supports high neural data rates but has little on-device compute.
Table 1: State-of-the-art BCI systems
Academic research labs have pursued other methods to develop BCIs. One approach has been to innovate at the circuit/VLSI layer to increase BCI functionality, exemplified by NeuralTree [7], and the other is to innovate at the architecture layer, such as with our work on HALO and SCALO. These approaches are not exclusive, but the emergence of these different trends also reminds us of the approaches that researchers in devices and computer architecture took to develop new machines or even teach computer design in the early days (e.g., see the SIGMICRO oral history [8] (Page 5 of the transcript) on the perspectives of Edward S. Davidson, an early architect and Nick Holonyak Jr, the inventor of the LED, on how to teach computer engineering at UIUC). While Holonyak was keen on a computer design curriculum based on solid-state physics and circuits, Davidson viewed computer design as architecture (like in construction2The term computer architecture, which referred to instruction set architecture hasn’t yet been coined then.) that worked with rules about devices (the bricks), but was less focused on how the bricks came to be. Over the years of course, we have seen many examples that joint innovation and co-design in architectures, circuits and devices can bring about.
NeuralTree is a BCI SoC that relies on new circuits to provide neural network training and inference on device, and supports multiple applications. It serves the rapidly growing set of BCI applications that aim to leverage ML for uses like epileptic seizure prediction, movement intent, and Parkisnon’s. NeuralTree is a significant milestone for real-time ML BCI applications, but further research is required to scale this approach for on-device learning (e.g., distributed or federated ML) across multiple brain regions.
We have been developing BCI architectures HALO and SCALO that flexibly support many BCI applications including both ML and non-ML methods, while supporting high data rates. HALO is a multi-accelerator BCI processor that is wireless, and can interface with up to 96 electrodes from on brain region. SCALO builds on this work using cross-layer co-design spanning wireless networking, on-device non-volatile-memory (NVM) storage, and compute to interface with multiple brain regions. SCALO enables for the first time, on-device distributed neural signal processing. We refer to the published work [1], [2] for details of these contributions to both computer architecture and neuro-engineering. It is the hard challenge of designing a BCI that has led us to these broadly useful innovations.
In addition to the devices in Table 1, there have been important advances in BCI design from several groups, which have also influenced our work with HALO and SCALO. Mastermind is a multi-accelerator SoC to support Hierarchical Wasserstein Alignment, an algorithm used for movement intent decoding and other applications. The Mastermind SoC is not implanted but supports online decoding by communicating wirelessly with an implanted BCI that transmits neural spike activity. uBrain brings DNN functionality to BCIs processing EEG data, by using simple unary computing operations to achieve hardware efficiency. Noema is a BCI accelerator design for spike sorting, which is widely used in neural decoding applications. Spike sorting separates the cumulative neural activity that BCI electrodes sense into per-neuron spikes. Noema is scalable for various forms of online deployment such as implanted, wearables, and dedicated SoC platforms. Finally, many works target algorithms for neural decoding, and present new opportunities for hardware co-design (e.g., this work that uses control theory based methods).
We have built on lessons from the prior work in this space while designing HALO and SCALO. For example, we have designed the accelerators in our processors to communicate directly with each other without CPU or software assistance, inspired from the peer-to-peer communication used in Mastermind. uBrain has led us to think about methods to incorporate neural network support on distributed BCIs, e.g., by using hierarchical decomposition, and co-designing the network with hardware. Noema has motivated us to develop on-chip support for spike sorting and offered new ways to support this challenging BCI application online. Sensing the need to facilitate algorithm-hardware co-design for a variety of methods from prior work, we have also included support for configurable linear algebra kernels in SCALO. More generally, these designs have also led us to think about developing distributed systems in and near the brain for providing more complex BCI functionality.
We are glad to see the exciting work towards enabling online neural decoding capabilities for BCIs. Achieving this, however, requires the composition of many styles of accelerators and research contributions. In fact, one reason why we made HALO/SCALO to be modular with a globally asynchronous locally synchronous (GALS) architecture is for it to serve as a base platform that can enable such research. Such a platform would also simplify the design of software stacks, which in in turn enable neuro-engineers to focus on application and algorithmic design without managing the underlying system complexity–something they cannot do so today. We’re also working towards launching a community-wide effort to develop a standardized suite of BCI applications, similar to MLPerf to facilitate architecture design and systems benchmarking in this challenging and diversified domain. We hope our efforts stimulate further research towards high-precision and high-bandwidth neural interfaces that will one day augment human cognition and decision-making.
About the Authors
Raghavendra (Raghav) Pothukuchi is an Associate Research Scientist, and an NSF/CRA Computing Innovation Fellow at Yale University. He works on BCIs, classical and quantum systems for cognitive modeling, and brain-inspired architectures. Raghav’s research on BCIs won the ISCA’23 best paper award, and his earlier work was selected to the IEEE Micro Top Picks. His work on mapping cognitive models to quantum computers is influencing Quantum Research Kernels, a community-wide effort led by Intel to guide future quantum architecture design. Raghav was also selected to the 2022 Heidelberg Laureate Forum as a young researcher.
Abhishek Bhattacharjee is a Professor of Computer Science at Yale University. He is also a faculty member of the Wu Tsai Institute for the brain sciences and the Yale Center for Brain & Mind Health. Abhishek’s research on address translation has influenced the design of billions of shipped microprocessors and operating systems. For these contributions, Abhishek was the recipient of the 2023 ACM SIGARCH Maurice Wilkes Award. More recently, he has also been working on microprocessors for neural interfaces. Abhishek teaches courses on computer architecture and the hardware/software interface, for which he was the recipient of Yale Engineering’s 2022 Ackerman Award.
References
[1] Karageorgos, I., Sriram, K., Veselý, J., Wu, M., Powell, M., Borton, D., Manohar, R. and Bhattacharjee, A., “Hardware-Software Co-Design for Brain-Computer Interfaces,” in International Symposium on Computer Architecture (ISCA), 2020.
[2] Sriram, K., Pothukuchi, R.P., Gerasimiuk, M., Ugur, M., Ye, O., Manohar, R., Khandelwal, A. and Bhattacharjee, A., “SCALO: An Accelerator-Rich Distributed System for Scalable Brain-Computer Interfacing,” in International Symposium on Computer Architecture (ISCA), 2023.
[3] Defining Surgical Terminology and Risk for Brain Computer Interface Technologies – Scientific Figure on ResearchGate. Available from: https://www.researchgate.net/figure/Anatomic-locations-of-representative-BCI-sensors-BCI-form-factors-have-sensors-in-a_fig1_350404476 [accessed 27 Dec, 2023] Creative Commons Attribution 4.0 International
[4] https://kordinglab.com/2016/01/06/bits-per-sec-human-brain.html
[5] Silay, K.M., Dehollain, C. and Declercq, M., “Numerical Analysis of Temperature Elevation in the Head Due to Power Dissipation in a Cortical Implant,” in International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), 2008.
[6] Stavisky, S.D., Rezaii, P., Willett, F.R., Hochberg, L.R., Shenoy, K.V. and Henderson, J.M., “Decoding Speech from Intracortical Multielectrode Arrays in Dorsal “Arm/Hand Areas” of Human Motor Cortex,” in International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), 2018.
[7] Shin, U., Ding, C., Zhu, B., Vyza, Y., Trouillet, A., Revol, E.C., Lacour, S.P. and Shoaran, M., “NeuralTree: A 256-channel 0.227-μJ/class Versatile Neural Activity Classification and Closed-Loop Neuromodulation SoC,” IEEE Journal of Solid-State Circuits, 57(11), pp.3243-3257, 2022
[8] Oral history of Edward S. Davidson, Interviewed by Prof. Paul N. Edwards, 2009. Transcript: https://www.sigmicro.org/media/oralhistories/davidson.pdf . Media: https://www.sigmicro.org/resources/oralhistories.php
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
- 1The term is a reference to The Infinite Brain (1930), one of the first works of fiction that described a device that can read the brain’s electrical activity and enables uploading the brain’s memories and intelligence into machines.
- 2The term computer architecture, which referred to instruction set architecture hasn’t yet been coined then.
